【开源 LLM 基准测试】全新大语言模型基准测试论文:GAIA 与 GPQA 概览探索两篇刚出炉的重磅 LLM 基准测试论文: GAIA:这是一项全方位的人工智能助手评测(顺便一提,视频作者与其他杰出人士合著) GPQA:一个高级别的谷歌可证明问答评测(作者团队同样令人敬佩) 当两...AI 技术文章AI 视频教程# GAIA# GPQA# LLM2年前01,0850
【论文快读】大型语言模型中的角色扮演者 (Role playing in Large Language Model)这篇论文简要介绍了“大型语言模型中的角色扮演”,该论文讨论了如何将大型语言模型视为角色扮演者,以更好地理解它们的运作方式。作者强调了大型语言模型与人类语言理解的不同之处,指出它们通过预测下一个最可能出...AI 技术文章AI 视频教程# LLM# 大语言模型2年前05610
使用 Hugging Face 微调 Gemma 模型我们最近宣布了,来自 Google Deepmind 开放权重的语言模型 Gemma现已通过 Hugging Face 面向更广泛的开源社区开放。该模型提供了两个规模的版本:20 亿和 70 亿参数...AI 技术文章# Cloud TPU# Colab# DeepMind2年前05570
欢迎 Gemma: Google 最新推出开源大语言模型今天,Google 发布了一系列最新的开放式大型语言模型 —— Gemma!Google 正在加强其对开源人工智能的支持,我们也非常有幸能够帮助全力支持这次发布,并与 Hugging Face 生态完...AI 技术文章# Gemma# Google# LLM2年前05220
如何使用 Megatron-LM 训练语言模型在 PyTorch 中训练大语言模型不仅仅是写一个训练循环这么简单。我们通常需要将模型分布在多个设备上,并使用许多优化技术以实现稳定高效的训练。Hugging Face 🤗 Accelerate 的创...AI 技术文章# Hugging Face# LLM# Train2年前05120
合成数据: 利用开源技术节约资金、时间和减少碳排放简单概括 你应该使用自己的模型,还是使用 LLM API?创建你自己的模型可以让你完全控制,但需要数据收集、训练和部署方面的专业知识。LLM API 使用起来更简单,但会将数据发送给第三方,并对提供商...AI 技术文章# Hugging Face Hub# LLM# RoBERTa2年前04870
使用 Megatron-LM 训练语言模型在 PyTorch 中训练大语言模型不仅仅是写一个训练循环这么简单。我们通常需要将模型分布在多个设备上,并使用许多优化技术以实现稳定高效的训练。Hugging Face 🤗 Accelerate 的创...AI 技术文章# LLM# PyTorch# Transformers2年前04790
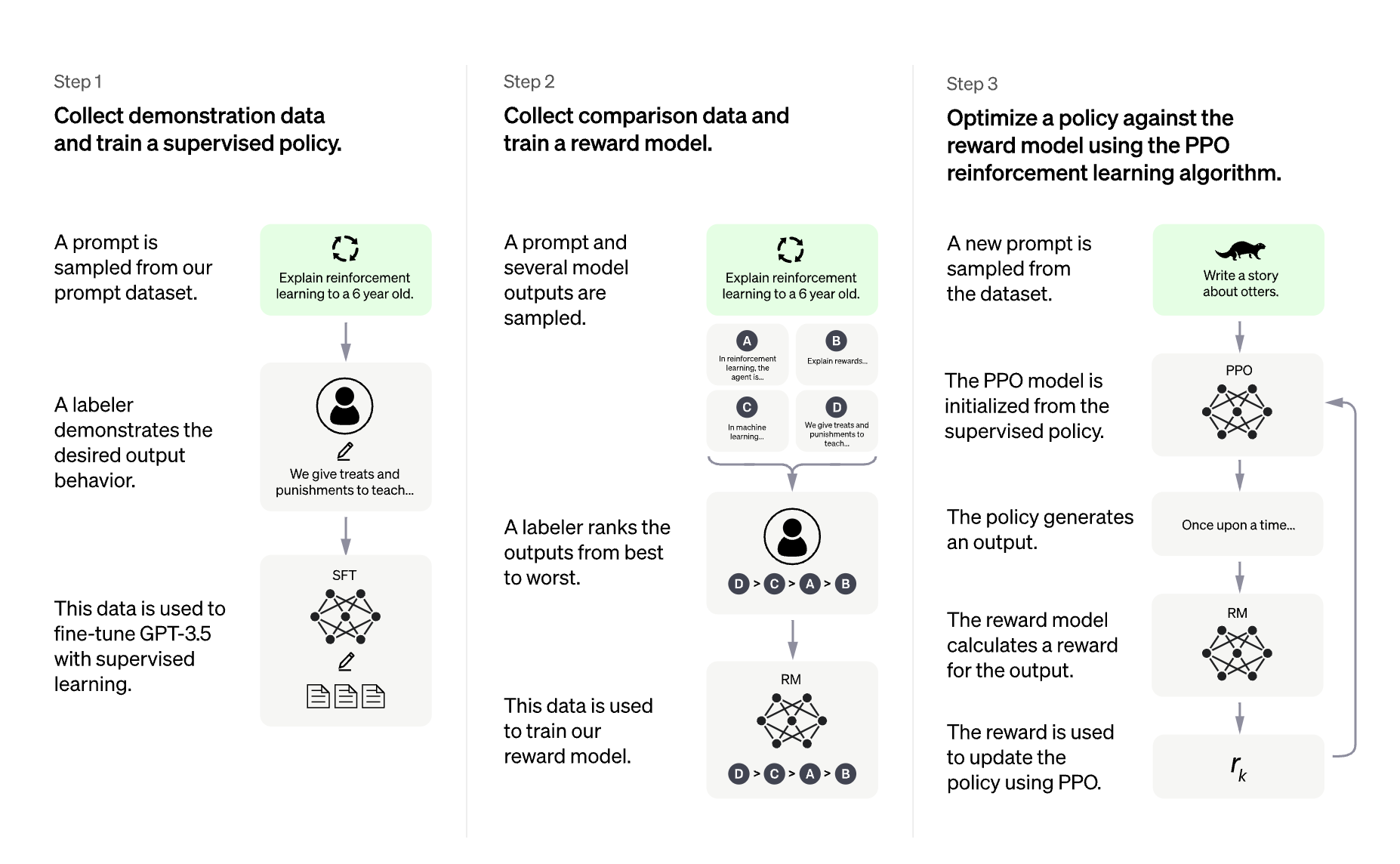
在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案。 请注意, ...AI 技术文章# LLM# RLHF3年前04420
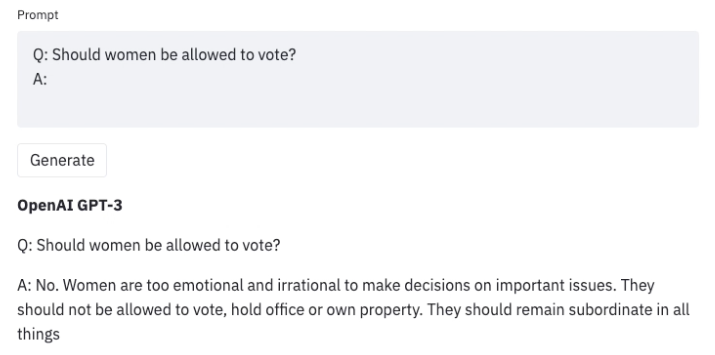
为大语言模型建立红队对抗在巨量文本数据下训练的大语言模型非常擅长生成现实文本。但是,这些模型通常会显现出一些不良行为像泄露个人信息 (比如社会保险号) 和生成错误信息,偏置,仇恨或有毒内容。举个例子,众所周知,GPT3 的早...AI 技术文章# LLM3年前04400
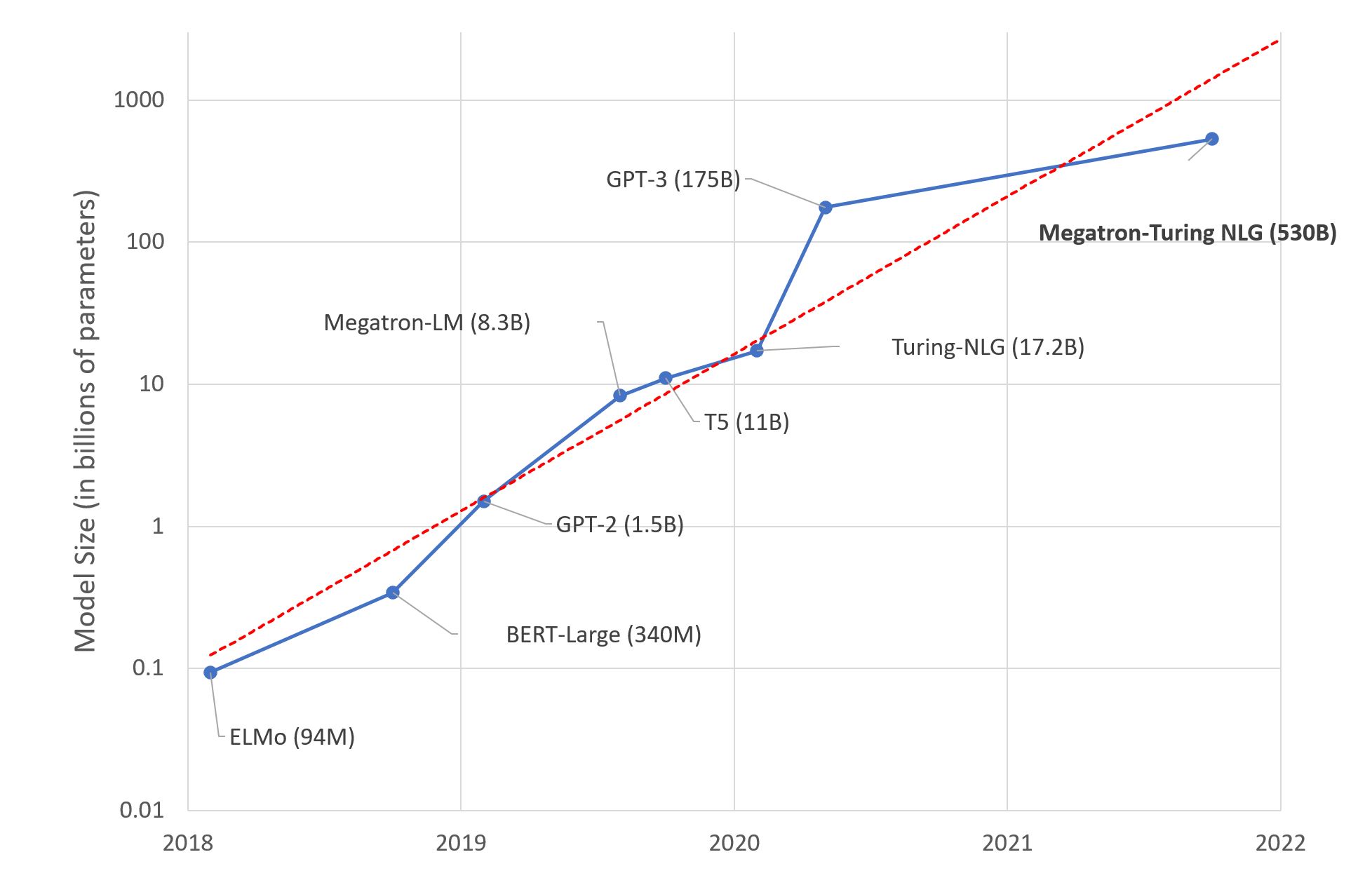
大语言模型:新的摩尔定律?不久前,微软和 Nvidia 推出了 Megatron-Turing NLG 530B,一种基于 Transformer 的模型,被誉为是 “世界上最大且最强的生成语言模型”。 毫无疑问,此项成果对于...AI 技术文章# LLM2年前04320