Codex 正在推动开源 AI 模型的训练与发布继我们使用 Claude Code 训练开源模型的项目之后,现在我们更进一步,将 Codex 引入这一流程。这里的重点不是“Codex 自己开源模型”,而是让 Codex 作为编码代理,参与并自动化开...AI 技术文章# Codex# 开源AI模型1个月前020
经同意的语音克隆在这篇博客文章中,我们介绍了“语音同意验证机制 (voice consent gate)”的概念,支持通过明确同意来进行语音克隆。我们还提供了一个 示例 Space 应用 和 相关代码,帮助大家快速上...AI 技术文章# 语音克隆1个月前020
流式数据集:效率提升 100 倍!快速了解(TLDR) 现在只需一行代码,就能通过 load_dataset('dataset', streaming=True) 以流式方式加载数据集,无需下载! 无需复杂配置、不...AI 技术文章# Datasets# 数据集1个月前030
huggingface_hub 1.0 正式版现已发布:开源机器学习基础五周年回顾简要总结: 经过五年的持续开发,huggingface_hub 发布 v1.0 正式版!这一里程碑标志着这个库的成熟与稳定。它已成为 Python 生态中支撑 20 万个依赖库 的核心组件,并提供访问...AI 技术文章# Hugging Face Hub2个月前010
Hugging Face 论文页面功能指南在飞速变化的研究世界中,紧跟最新进展至关重要。为帮助开发者与研究人员把握 人工智能 前沿动态,我们推出了 Daily Papers 页面。自上线以来,Daily Papers 已收录超过 1 万 篇由...AI 技术文章# Daily Papers2个月前070
用开源模型强化你的 OCR 工作流我们在这篇文章中新增了 Chandra 和 OlmOCR-2,并附上了它们在 OlmOCR 基准上的得分 🫡 摘要: 强大的视觉语言模型 (Vision-Language Models, VLMs) ...AI 技术文章# OCR# 开源模型2个月前040
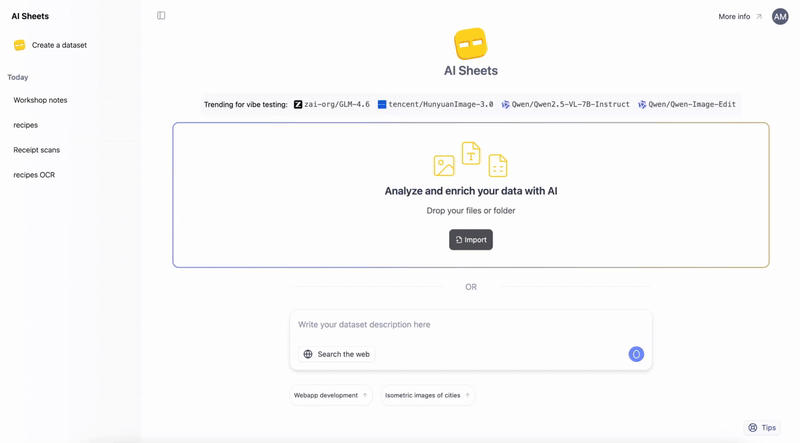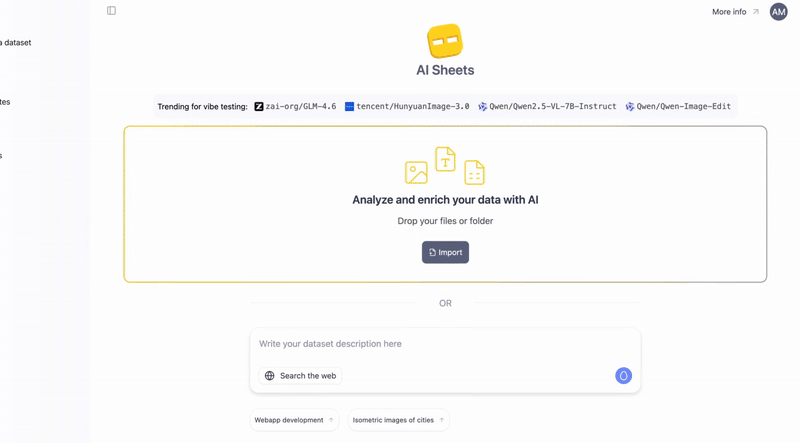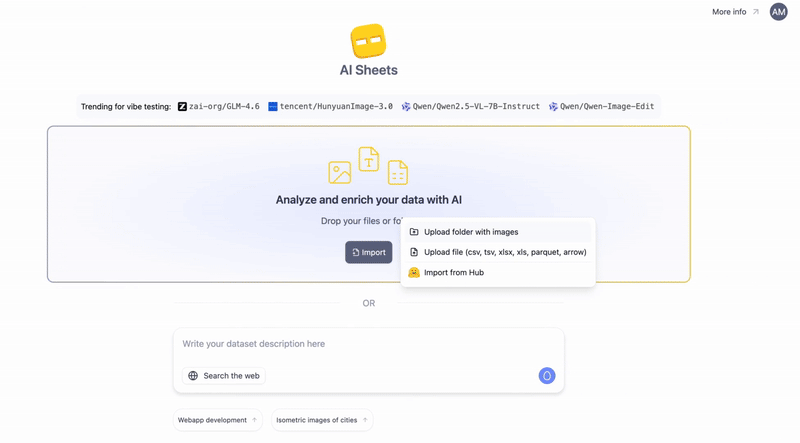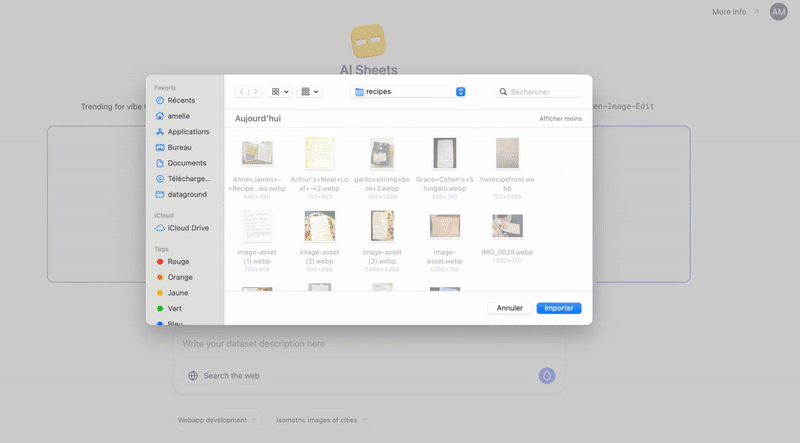
用 AI Sheets 解锁图像的力量🧭简要概览:Hugging Face AI Sheets 是一款开源工具,能够用 AI 模型增强数据集的处理能力,无需编写任何代码。现在新增视觉功能:可以从图像 (如收据、文档) 中提取数据、根据文本...AI 技术文章# AI 图像# HuggingFace2个月前020
LeRobot v0.4.0 正式发布:全面提升开源机器人的学习能力我们非常高兴地宣布,LeRobot 迎来一系列重大升级,让开源的机器人学习比以往更强大、更可扩展、也更易用!从重构的数据集到灵活的编辑工具、新的仿真环境,以及面向硬件的全新插件系统,LeRobot 正...AI 技术文章# LeRobot# 开源机器人3个月前0170
HF Papers 直播| 多模态专场由 Hugging Face × OpenMMLab × ModelScope × 知乎 × 机智流 等联合发起的【AI Insight Talk】系列直播活动第四场 - 多模态专场就在明天! 各家多...AI 直播活动6个月前030
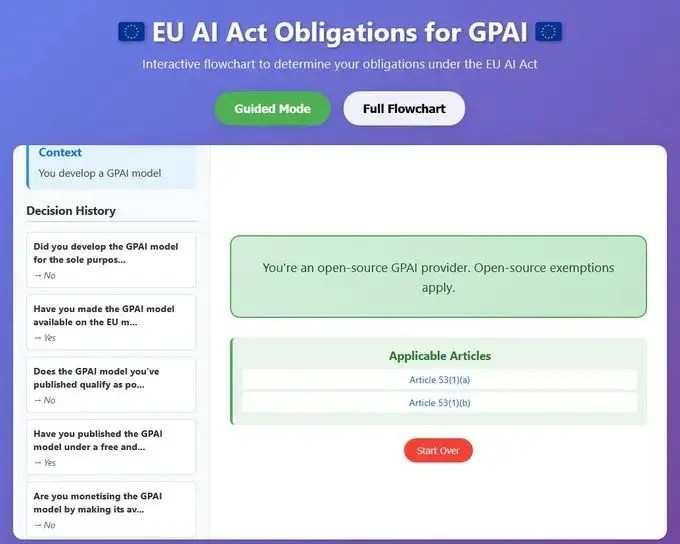
开源开发者须知:欧盟《人工智能法案》对通用人工智能模型的最新要求⚠️ 本文不构成任何法律意见或建议。 快速摘要 (TL;DR): 自 2025 年 8 月 2 日起,欧盟《人工智能法》将对通用人工智能(GPAI)模型的提供者模型提供者提出新的合规要求。但是对于用于...AI 技术文章# 人工智能法案# 开源6个月前010