一次失败的实验 – 无限注意力,我们为什么坚持实验总结: 随着我们增加内存压缩次数的次数,Infini-attention 的性能会变得越来越差。据我们所知,ring attention、YaRN 和 rope scaling 这三种方法仍是将预训练...AI 技术文章# 无限注意力1年前02180
为数据集而生的 SQL 控制台随着数据集的使用量急剧增加,Hugging Face 社区已经变成了众多数据集默认存放的仓库。每月,海量数据集被上传到社区,这些数据集亟需有效的查询、过滤和发现。 每个月在 Hugging Face ...AI 技术文章# SQL# 数据集1年前02120
揭秘 FineVideo 数据集构建的背后的秘密开放视频数据集稀缺,因此减缓了开源视频 AI 的发展。为此,我们构建了 FineVideo,这是一个包含 43,000 个视频的数据集,总时长为 3,400 小时,并带有丰富的描述、叙事细节、场景分割...AI 技术文章# Datasets# FineVideo# 数据集1年前02100
NuminaMath 是如何荣膺首届 AIMO 进步奖的?今年,Numina 和 Hugging Face 合作角逐 AI 数学奥林匹克 (AI Math Olympiad,AIMO) 的首届进步奖。此次比赛旨在对开放 LLM 进行微调,以使其能解决高中难度...AI 技术文章# AIMO# NuminaMath1年前02100
LAVE: 使用 LLM 对 Docmatix 进行零样本 VQA 评估 – 我们还需要微调吗?在开发 Docmatix 时,我们发现经其微调的 Florence-2 在 DocVQA 任务上表现出色,但在基准测试中得分仍比较低。为了提高基准测试得分,我们必须在 DocVQA 数据集上进一步对模...AI 技术文章# Docmatix# LAVE# LLM1年前02090
TGI 多-LoRA: 部署一次,搞定 30 个模型的推理服务你是否已厌倦管理多个 AI 模型所带来的复杂性和高成本? 那么, 如果你可以部署一次就搞定 30 个模型推理服务会如何? 在当今的 ML 世界中,哪些希望充分发挥其数据的价值的组织可能最终会进入一个...AI 技术文章# LoRA# TGI1年前02090
Google 最新发布: Gemma 2 2B、ShieldGemma 和 Gemma Scope在发布 Gemma 2 一个月后,Google 扩展了其 Gemma 模型系列,新增了以下几款: Gemma 2 2B - 这是 Gemma 2 的 2.6B 参数版本,是设备端使用的理想选择。 Sh...AI 技术文章# Gemma 2# Gemma Scope# ShieldGemma1年前02080
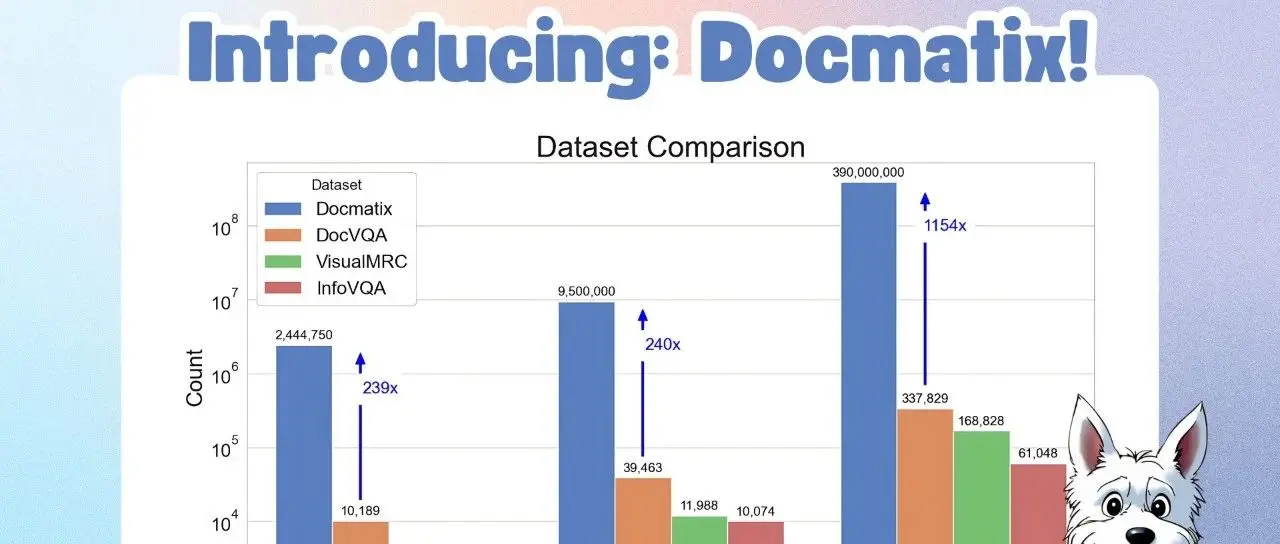
Docmatix – 超大文档视觉问答数据集本文,我们将发布 Docmatix - 一个超大的文档视觉问答 (DocVQA) 数据集,比之前的数据集大 100 倍。当使用 Docmatix 微调 Florence-2 时,消融实验显示 DocV...AI 技术文章# Docmatix1年前02050
ggml 简介ggml 是一个用 C 和 C++ 编写、专注于 Transformer 架构模型推理的机器学习库。该项目完全开源,处于活跃的开发阶段,开发社区也在不断壮大。ggml 和 PyTorch、Tensor...AI 技术文章# ggml# Hugging Face1年前02050
基于 Quanto 和 Diffusers 的内存高效 transformer 扩散模型过去的几个月,我们目睹了使用基于 transformer 模型作为扩散模型的主干网络来进行高分辨率文生图 (text-to-image,T2I) 的趋势。和一开始的许多扩散模型普遍使用 UNet 架构...AI 技术文章# Diffusers# Quanto# Transformers1年前02030