
内容目录
简介
ControlNet 这个神经网络模型使得用户可以通过施加额外条件,细粒度地控制扩散模型的生成过程。这一技术最初由 Adding Conditional Control to Text-to-Image Diffusion Models 这篇论文提出,并很快地风靡了扩散模型的开源社区。作者开源了 8 个不同的模型,使得用户可以用 8 种条件去控制 Stable Diffusion 模型(包括版本 1 到 5 )。这 8 种条件包括姿态估计、深度图、边缘图、素描图 等等。

在这篇博客中,我们首先介绍训练 Uncanny Faces model 的步骤。这是一个基于 3D 合成人脸的人脸姿态模型(这里的 uncanny faces 只是一个无意得到的结果,后面我们会讲到)。
开始着手用 Stable Diffusion 训练你的 ControlNet
训练你自己的 ControlNet 需要 3 个步骤:
设计你想要的生成条件: 使用 ControlNet 可以灵活地“驯服” Stable Diffusion,使它朝着你想的方向生成。预训练的模型已经展示出了大量可用的生成条件,此外开源社区也已经开发出了很多其它条件,比如这里 像素化的色彩板。
构建你自己的数据集: 当生成条件确定好后,就该构建数据集了。你既可以从头构建一个数据集,也可以使用现有数据集中的数据。为了训练模型,这个数据集需要有三个维度的信息: 图片、作为条件的图片,以及语言提示。
训练模型: 一旦数据集建好了,就可以训练模型了。如果你使用 这个基于 diffusers 的训练脚本,训练其实是最简单的。这里你需要一个至少 8G 显存的 GPU。
1. 设计你想要的生成条件
在设计你自己的生成条件前,有必要考虑一下两个问题:
- 哪种生成条件是我想要的?
- 是否已有现存的模型可以把正常图片转换成我的条件图片?
举个例子,假如我们想要使用人脸特征点作为生成条件。我们的思考过程应该是这样: 1. 一般基于特征点的 ControlNet 效果都还挺好。2. 人脸特征点检测也是一个很常见的任务,也有很多模型可以在普通图片上检测人脸特征点。3. 让 Stable Diffusion 去根据特征点生成人脸图片也挺有意思,还能让生成的人脸模仿别人的表情。

2. 构建你自己的数据集
好!那我们现在已经决定用人脸特征点作为生成条件了。接下来我们需要这样构建数据集:
- 准备 ground truth 图片 (
image): 这里指的就是真实人脸图片 - 准备 条件图片 (
conditioning_image): 这里指的就是画出来的特征点 - 准备 说明文字 (
caption): 描述图片的文字
针对这个项目,我们使用微软的 FaceSynthetics 数据集: 这是一个包含了 10 万合成人脸的数据集。你可能会想到其它一些人脸数据集,比如 Celeb-A HQ 和 FFHQ,但这个项目我们决定还是采用合成人脸。

这里的 FaceSynthetics 数据集看起来是个不错的选择: 它包含了真实的人脸图片,同时也包含了被标注过的人脸特征点(按照 iBUG 68 特征点的格式),同时还有人脸的分割图。

然而,这个数据集也不是完美的。我们前面说过,我们应该有模型可以将真实图片转换到条件图片。但这里似乎没有这样的模型,把人脸图片转换成我们特征点标注形式(无法把特征点转换为分割图)。

所以我们需要用另一种方法:
- 使用
FaceSynthetics中的真实图片 (image) - 使用一个现有的模型把人脸图片转换为 68 个特征点的形式。这里我们使用 SPIGA 这个模型
- 使用自己的代码把人脸特征点转换为人脸分割图,以此作为“条件图片” (
conditioning_image) - 把这些数据保存为 Hugging Face Dataset
这里 是将真实图片转换到分割图的代码,以及将数据保存为 Hugging Face Dataset 的代码。
现在我们准备好了 ground truth 图片和“条件图片”,我们还缺少说明文字。我们强烈推荐你把说明文字加进去,但你也可以试试使用空的说明文字来看看效果。因为 FaceSynthetics 数据集并没有自带说明文字,我们使用 BLIP captioning 去给图片加上文字(代码在这里)。
至此,我们就完成了数据集的构建。这个 Face Synthetics SPIGA with captions 数据集包含了 ground truth 图片、条件图片,以及对应的说明文字,总计有 10 万条数据。一切就绪,我们现在可以开始训练模型了。

3. 模型训练
有了 数据,下一步就是训练模型。即使这部分很难,但有了 下面的脚本,这个过程却变成了最简单的部分。我们用了一个 A100 GPU去训练(在 LambdaLabs 每小时 1.1 美元租的)。
我们的训练经验
我们以 batch size 为 4 训练了 3 个 epoch。结果表明此策略有些太激进,导致结果出现过拟合现象。模型有点忘记人脸的概念了,即使提示语中包含“怪物史莱克”或“一只猫”,模型也只会生成人脸而不是“史莱克”或猫;同时模型也对各种风格变得不敏感。
如果我们只训练 1 个 epoch (即模型仅学习了 10 万张照片),模型倒是能遵循输入的姿态,同时也没什么过拟合。看起来还行,但由于我们用的是合成数据,模型最终生成的都是些看起来很 3D 的人脸,而不是真实人脸。当然,基于我们用的数据集,生成这样的效果也正常。这里是训练好的模型: uncannyfaces_25K。
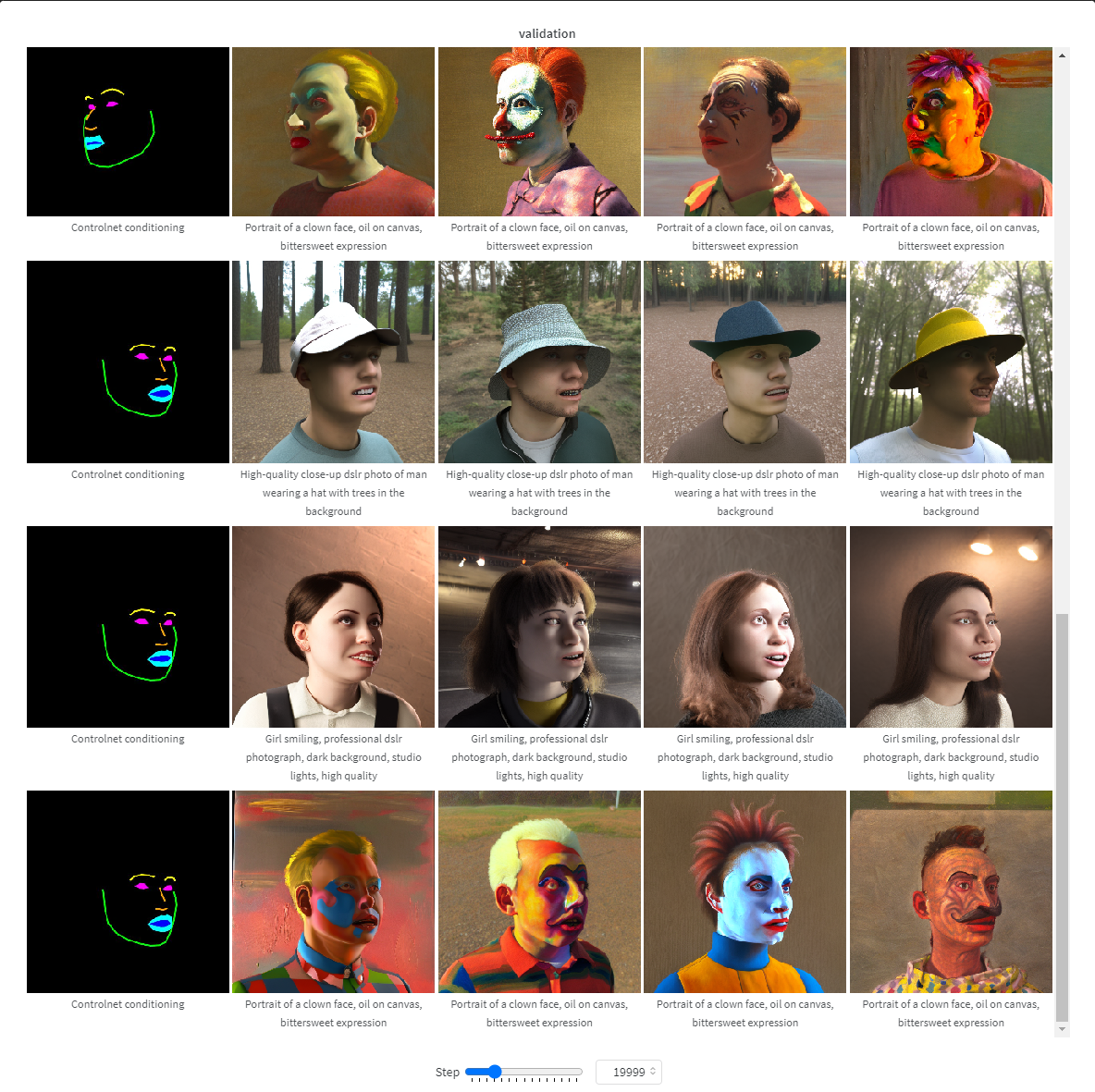
在这张可交互表格 (请访问下面的链接) 中,你可以看看不同步数下模型训练进度如何。在训练了大约 15k 步后,模型就已经开始学习姿态了。最终模型在 25k 步后成熟。
训练具体怎么做
首先我们安装各种依赖:
pip install git+https://github.com/huggingface/diffusers.git transformers accelerate xformers==0.0.16 wandb
huggingface-cli login
wandb login 然后运行这个脚本 train_controlnet.py
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--output_dir="model_out" \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./face_landmarks1.jpeg" "./face_landmarks2.jpeg" "./face_landmarks3.jpeg" \
--validation_prompt "High-quality close-up dslr photo of man wearing a hat with trees in the background" "Girl smiling, professional dslr photograph, dark background, studio lights, high quality" "Portrait of a clown face, oil on canvas, bittersweet expression" \
--train_batch_size=4 \
--num_train_epochs=3 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
--report_to wandb \
--push_to_hub我们详细看看这些设置参数,同时也看看有哪些优化方法可以用于 8GB 以下显存的 GPU 训练。
pretrained_model_name_or_path: 基础的 Stable Diffusion 模型,这里我们使用 v2-1 版本,因为这一版生成人脸效果更好output_dir: 保存模型的目录文件夹dataset_name: 用于训练的数据集,这里我们使用 Face Synthetics SPIGA with captionsconditioning_image_column: 数据集中包含条件图片的这一栏的名称,这里我们用spiga_segimage_column: 数据集中包含 ground truth 图片的这一栏的名称,这里我们用imagecaption_column: 数据集中包含文字说明的这一栏的名称,这里我们用image_captionresolution: ground truth 图片和条件图片的分辨率,这里我们用512x512learning_rate: 学习率。我们发现设成1e-5效果很好,但你也可以试试介于1e-4和2e-6之间的其它值validation_image: 这里是让你在训练过程中偷窥一下效果的。每隔validation_steps步训练,这些验证图片都会跑一下,让你看看当前的训练效果。请在这里插入一个指向一系列条件图片的本地路径validation_prompt: 这里是一句文本提示,用于和你的验证图片一起验证当前模型。你可以根据你的需要设置train_batch_size: 这是训练时使用的 batch size。因为我们用的是 V100,所以我们还有能力把它设成 4。但如果你的 GPU 显存比较小,我们推荐直接设成 1。num_train_epochs: 训练模型使用的轮数。每一轮模型都会看一遍整个数据集。我们实验用的是 3 轮,但似乎最好的结果应该是出现在一轮多一点的地方。当训练了 3 轮时,我们的模型过拟合了。checkpointing_steps: 每隔这么多步,我们都会保存一下模型的中间结果检查点。这里我们设置成 5000,也就是每训练 5000 步就保存一下检查点。validation_steps: 每隔这么多步,validation_image和validation_prompt就会跑一下,来验证训练过程。report_to: 向哪里报告训练情况。这里我们使用 Weights and Biases 这个平台,它可以给出美观的训练报告。push_to_hub: 将最终结果推到 Hugging Face Hub.
但是将 train_batch_size 从 4 减小到 1 可能还不足以使模型能够在低配置 GPU 上运行,这里针对不同 GPU 的 VRAM 提供一些其它配置信息:
适配 16GB 显存的 GPU
pip install bitsandbytes
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam这里 batch size 设为 1,同时使用 4 步的梯度累计等同于你使用原始的 batch size 为 4 的情况。除此之外,我们开启了对梯度保存检查点,以及 8 bit 的 Adam 优化器训练,以此更多地节省显存。
适配 12GB 显存的 GPU
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
--set_grads_to_none适配 8GB 显存的 GPU
请参考 我们的教程
4. 总结
训练 ControlNet 的过程非常有趣。我们已经成功地训练了一个可以模仿真实人脸姿态的模型。然而这个模型更多是生成 3D 风格的人脸图片而不是真实人脸图片,这是由于我们使用了合成人脸的数据执行训练。当然这也让生成的模型有了独特的魅力。
试试我们的 Hugging Face Space
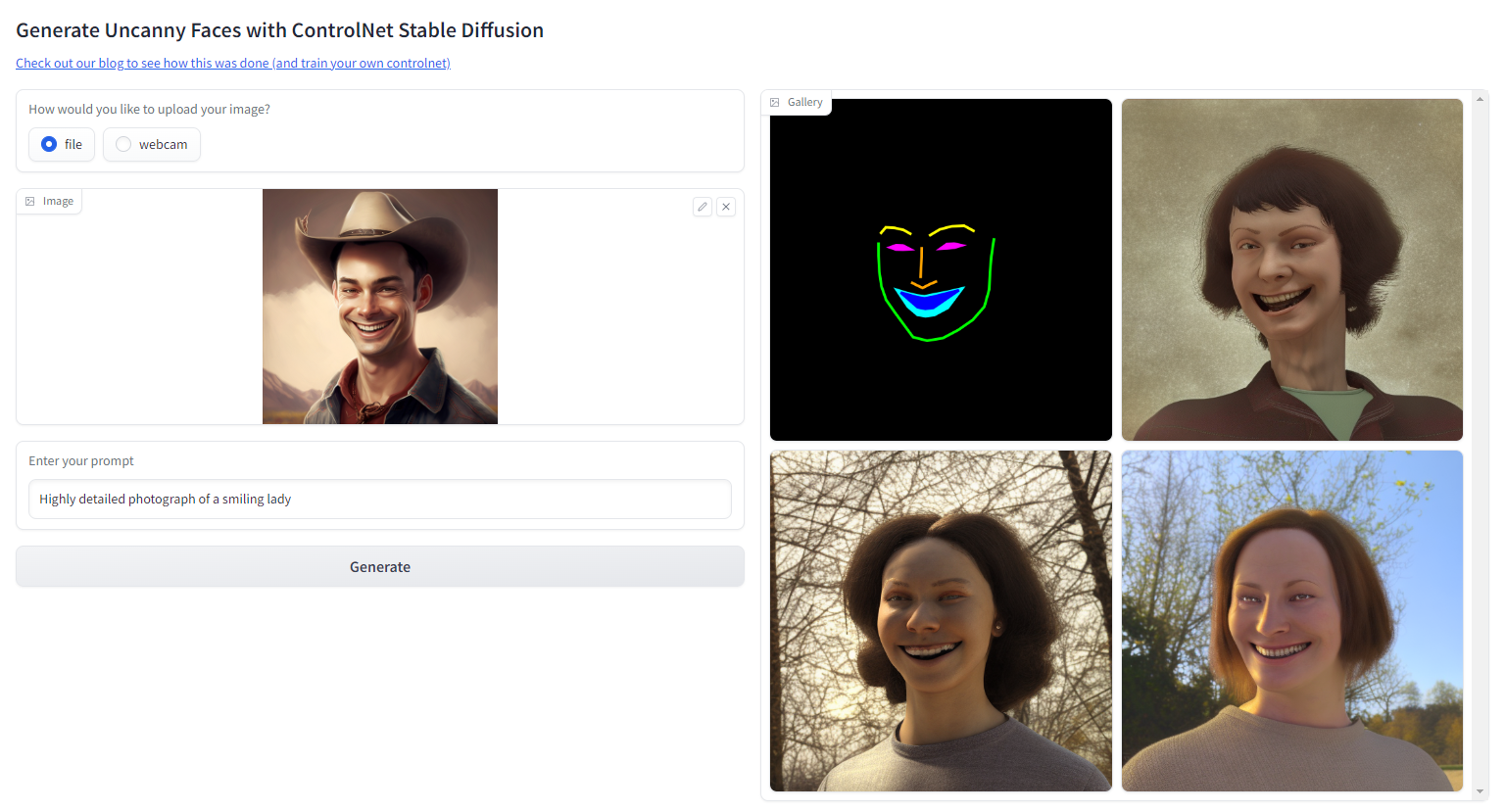
下一步,为了生成真实的人脸图片,同时还不使用真实人脸数据集,我们可以用 Stable Diffusion Image2Image 跑一遍所有的 FaceSynthetics 图片,把看起来很 3D 的人脸转换成真实人脸图片,然后再训练 ControlNet。
请继续关注我们,接下来我们将举办 ControlNet 训练赛事。请在 Twitter 关注 Hugging Face,或者加入我们的 Discord 以便接收最新消息!
如果您此前曾被 ControlNet 将 Lofi Girl 的动画形象改成写实版类真人画面的能力折服,却又担心自己难以承担高昂的训练成本,不妨报名参加我们近期的提供免费 TPU 的 ControlNet 微调活动。试试看充满创造力的你能有什么样的大作!
赞赏英文原文: https://hf.co/blog/train-your-controlnet
作者: Apolinário from multimodal AI art, Pedro Cuenca
译者: HoiM Y, 阿东
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...