
内容目录
概要
开源大型语言模型 (LLMs) 现已达到一种性能水平,使它们适合作为推动智能体工作流的推理引擎: Mixtral 甚至在我们的基准测试中 超过了 GPT-3.5,并且通过微调,其性能可以轻易的得到进一步增强。
引言
针对 因果语言建模 训练的大型语言模型 (LLMs) 可以处理广泛的任务,但它们经常在逻辑、计算和搜索等基本任务上遇到困难。最糟糕的情况是,它们在某个领域,比如数学,表现不佳,却仍然试图自己处理所有计算。
为了克服这一弱点,除其他方法外,可以将 LLM 整合到一个系统中,在该系统中,它可以调用工具: 这样的系统称为 LLM 智能体。
在这篇文章中,我们将解释 ReAct 智能体的内部工作原理,然后展示如何使用最近在 LangChain 中集成的 ChatHuggingFace 类来构建它们。最后,我们将几个开源 LLM 与 GPT-3.5 和 GPT-4 进行基准测试。
什么是智能体?
LLM 智能体的定义非常宽泛: 它们指的是所有将 LLMs 作为核心引擎,并能够根据观察对其环境施加影响的系统。这些系统能够通过多次迭代“感知 ⇒ 思考 ⇒ 行动”的循环来实现既定任务,并常常融入规划或知识管理系统以提升其表现效能。你可以在 Xi et al., 2023 的研究中找到对智能体领域综述的精彩评述。
今天,我们将重点放在 ReAct 智能体 上。ReAct 采用一种基于“推理 (Reasoning)”与“行动 (Acting)”结合的方式来构建智能体。在提示词中,我们阐述了模型能够利用哪些工具,并引导它“逐步”思考 (亦称为 思维链 行为),以规划并实施其后续动作,达成最终的目标。
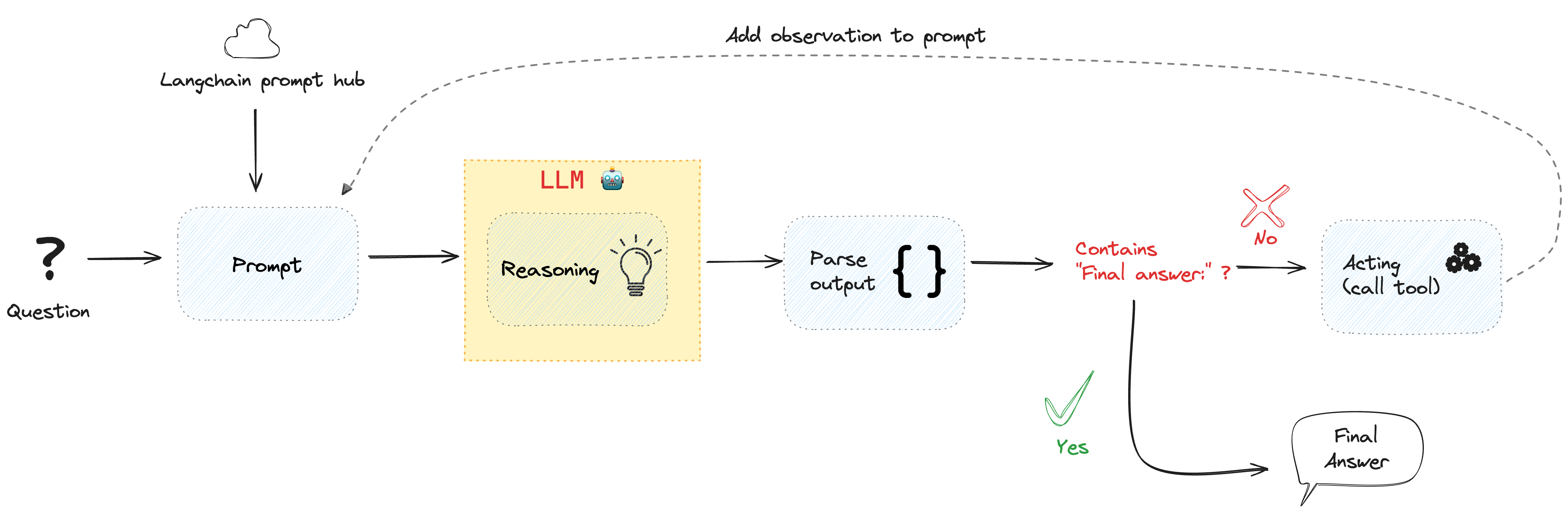
ReAct 智能体内部工作原理示例
上述图解虽显得有些抽象,但其核心原理其实相当直接。
参见 此笔记本: 我们借助 Transformers 库展示了一个最基础的工具调用实例。
本质上,LLM 通过一个循环被调用,循环中的提示包含如下内容:
这里是一个问题: “{question}”
你可以使用这些工具: {tools_descriptions}。
首先,你需要进行‘思考: {your_thoughts}’,接下来你可以:
- 以正确的 JSON 格式发起工具调用,
- 或者,以‘最终答案:’为前缀来输出你的答案。接下来,你需要解析 LLM 的输出:
- 如果输出中包含
‘最终答案:’字符串,循环便结束,并输出该答案; - 若不包含,则表示 LLM 进行了工具调用: 你需解析此输出以获得工具的名称及其参数,随后根据这些参数执行相应工具的调用。此工具调用的结果将被追加至提示信息中,然后你将带有这些新增信息的提示再次传递给 LLM,直至它获得足够的信息来给出问题的最终答案。
例如,LLM 的输出在回答问题: 1:23:45 中有多少秒? 时可能看起来像这样:
思考: 我需要将时间字符串转换成秒。
动作:
{
"action": "convert_time",
"action_input": {
"time": "1:23:45"
}
}鉴于此输出未包含 ‘最终答案:’ 字符串,它代表进行了工具调用。因此我们解析该输出,获取工具调用的参数: 以参数 {"time": "1:23:45"} 调用 convert_time 工具,执行该工具调用后返回 {'seconds': '5025'} 。
于是,我们将这整个信息块追加至提示词中。
更新后的提示词现在变为 (更为详尽的版本):
这是一个问题: “1:23:45 包含多少秒?”
你可以使用以下工具:
- convert_time: 将小时、分钟、秒格式的时间转换为秒。
首先,进行“思考: {your_thoughts}”,之后你可以:
- 使用正确的 JSON 格式调用工具,
- 或以“最终答案:”为前缀输出你的答案。
思考: 我需要把时间字符串转换成秒数。
行动:
{
"action": "convert_time",
"action_input": {
"time": "1:23:45"
}
}
观测结果: {'seconds': '5025'}➡️ 我们用这个新的提示再次调用 LLM,鉴于它可以访问工具调用结果中的 观测结果 ,LLM 现在最有可能输出:
思考: 我现在有了回答问题所需的信息。
最终答案: 1:23:45 中有 5025 秒。任务就这样完成了!
智能体系统的挑战
一般来说,运行 LLM 引擎的智能体系统的难点包括:
从提供的工具中选择一个能够帮助实现目标的工具: 例如,当询问
“大于 30,000 的最小质数是什么?”时,智能体可能会调用“K2 的高度是多少?”的Search工具,但这并无帮助。以严格的参数格式调用工具: 例如,在尝试计算一辆汽车 10 分钟内行驶 3 公里的速度时,你必须调用
Calculator工具,通过distance除以time来计算: 即便你的 Calculator 工具接受 JSON 格式的调用{“tool”: “Calculator”, “args”: “3km/10min”},也存在许多陷阱,例如:- 工具名称拼写错误:
“calculator”或“Compute”是无效的 - 提供的是参数名称而非其值:
“args”: “distance/time” - 格式非标准化:
“args": "3km in 10minutes”
- 工具名称拼写错误:
高效地吸收和利用过去观察到的信息,无论是初始上下文还是使用工具后返回的观察结果。
那么,完整的智能体设置会是怎样的呢?
使用 LangChain 运行智能体
我们刚刚在 🦜🔗LangChain 中集成了一个 ChatHuggingFace 封装器,使你能够基于开源模型创建智能体。
创建 ChatModel 并为其配备工具的代码非常简单,你可以在 Langchain 文档 中查看所有相关代码。
from langchain_community.llms import HuggingFaceHub
from langchain_community.chat_models.huggingface import ChatHuggingFace
llm = HuggingFaceHub(
repo_id="HuggingFaceH4/zephyr-7b-beta",
task="text-generation",
)
chat_model = ChatHuggingFace(llm=llm)你可以通过为其提供 ReAct 风格的提示词和工具,将 chat_model 转化为一个智能体:
from langchain import hub
from langchain.agents import AgentExecutor, load_tools
from langchain.agents.format_scratchpad import format_log_to_str
from langchain.agents.output_parsers import (
ReActJsonSingleInputOutputParser,
)
from langchain.tools.render import render_text_description
from langchain_community.utilities import SerpAPIWrapper
# 设置工具
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 设置 ReAct 风格的提示词
prompt = hub.pull("hwchase17/react-json")
prompt = prompt.partial(
tools=render_text_description(tools),
tool_names=", ".join([t.name for t in tools]),
)
# 定义智能体
chat_model_with_stop = chat_model.bind(stop=["\nObservation"])
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_log_to_str(x["intermediate_steps"]),
}
| prompt
| chat_model_with_stop
| ReActJsonSingleInputOutputParser()
)
# 实例化 AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "Who is the current holder of the speed skating world record on 500 meters? What is her current age raised to the 0.43 power?"
}
)智能体将处理如下输入:
思考: 为了回答这个问题,我需要找出当前速滑世界纪录保持者的年龄。我将使用搜索工具来获取这些信息。
行动:
{
"action": "search",
"action_input": " 速滑 500 米世界纪录保持者的年龄 "
}
观察: ...智能体对决: 开源 LLM 作为通用推理智能体的表现如何?
你可以在 这里 找到这个基准测试的代码。
评估
我们旨在评估开源大型语言模型 (LLMs) 作为通用推理智能体的表现。因此,我们选择了需要运用逻辑和使用基本工具 (如计算器和互联网搜索访问) 的问题。
最终数据集 是从其他三个数据集中选取样本的组合:
- 为了测试互联网搜索能力,我们选取了 HotpotQA 中的问题: 虽然这是一个检索型数据集,但它也可用于需要互联网访问的通用问题解答。有些问题原本需要结合来自不同来源的信息: 在我们的设置中,这意味着需要进行多步互联网搜索以整合结果。
- 对于计算器的应用,我们加入了来自 GSM8K 的问题: 这个数据集测试小学数学能力,并且完全可以通过正确利用 4 个运算符 (加、减、乘、除) 来解决。
- 我们还从 GAIA 中挑选了问题,这是一个对通用 AI 助理来说极具挑战性的基准测试。原始数据集中的问题可能需要许多其他不同的工具,如代码解释器或 PDF 阅读器: 我们精选了那些仅需搜索和计算器的问题。
评估采用了 GPT-4 作为评判员,基于 Prometheus 提示格式 的提示进行,结果以 5 点李克特量表 (5-point Likert Scale) 表示: 具体的提示内容可在 此处 查看。
模型
我们评估了一些强大的开源模型:
- Llama2-70b-chat
- Mixtral-8x7B-Instruct-v0.1
- OpenHermes-2.5-Mistral-7B
- Zephyr-7b-beta
- SOLAR-10.7B-Instruct-v1.0
这些模型通过 LangChain 的 ReAct 实现 进行了评估
这意味着我们引导它们按照以下格式输出函数调用:
{
"action": $TOOL_NAME,
"action_input": $INPUT
}作为比较,我们还利用 LangChain 的 专为 OpenAI 设计的智能体 对 GPT-3.5 和 GPT-4 在相同的例子上进行了评估。
由于这涉及到它们自己的函数调用模板,并在此基础上进行了微调,这意味着 OpenAI 模型应当展现出最佳性能。
结果
鉴于开源模型并没有针对特定的输出格式进行特别的函数调用微调,相较于 OpenAI 智能体,它们处于稍微不利的位置。
尽管存在这样的不利条件,某些模型的表现依然非常优秀!💪
这是 Mixtral-8x7B 回答“贵阳和塔城哪个城市人口更多?”问题的示例:
思考: 为了回答这个问题,我需要找到贵阳和塔城当前的人口数。我将利用搜索工具来查询这些信息。
操作:
{
"action": "search",
"action_input": " 贵阳当前人口 "
}
4.697 百万 (2016 年)
思考: 我已获得贵阳的人口数,为 4.697 百万 (截至 2016 年)。现在,我将再次使用搜索工具来确定塔城的人口数。
操作:
{
"action": "search",
"action_input": " 塔城当前人口 "
}
人口: 新疆: 塔城的数据在 2021 年报告为 1,110,000 人。这比 2020 年的 1,138,638 人有所下降。
人口: 新疆: 塔城的数据每年更新,从 2005 年 12 月到 2021 年,平均人口为 1,023,000 人,共 17 次观察。
我已确定塔城的人口约为 1.11 百万 (截至 2021 年)。对比两地人口,贵阳的人口超过塔城。
思考: 我现在清楚最终答案了
最终答案: 贵阳的人口更多,约为 4.697 百万 (截至 2016 年),而塔城的人口约为 1.11 百万 (截至 2021 年)。这是各模型在我们的评估数据集上的基准测试结果 (原始平均分按 1-5 的评分量表,已转换为 0-100%的量表以便阅读):
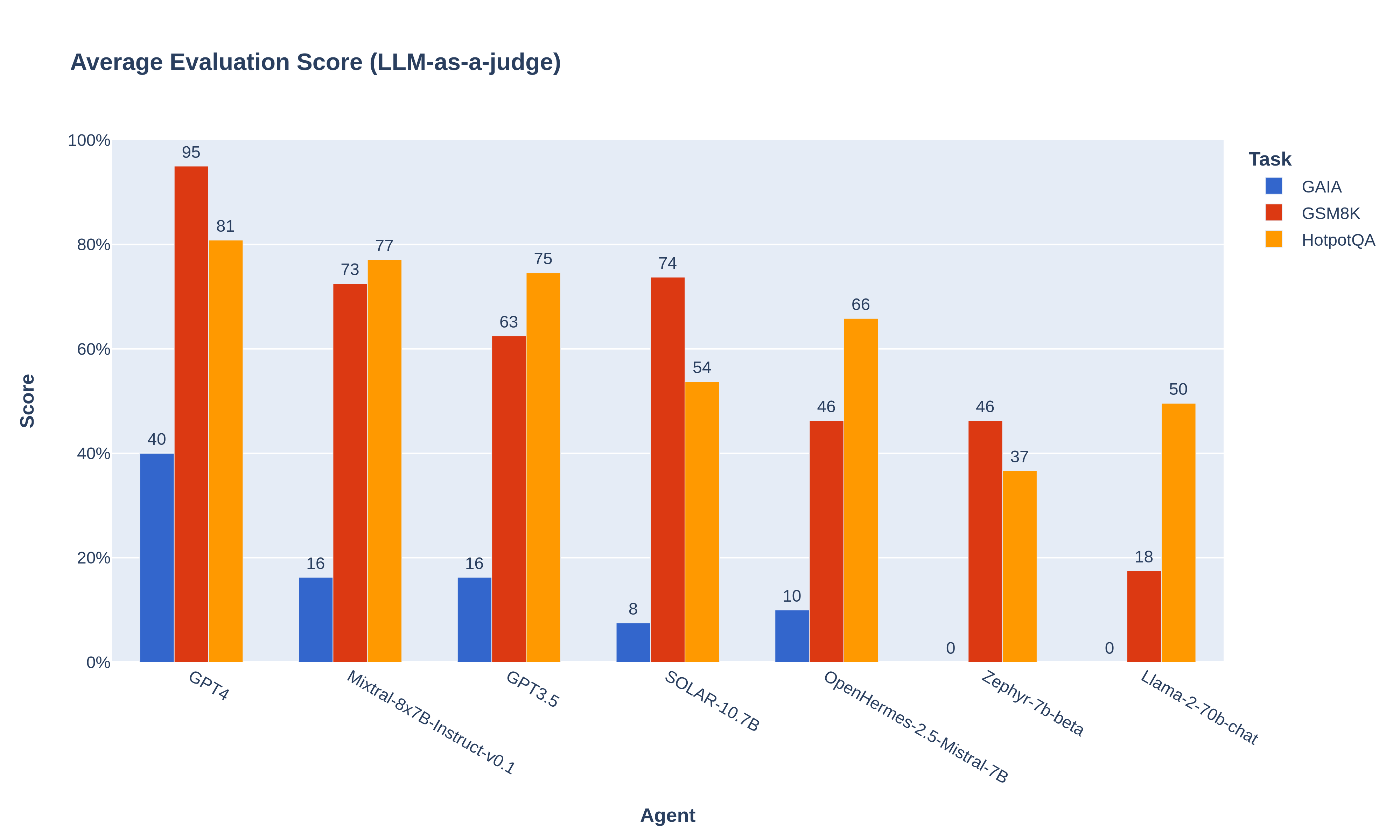
正如所见,一些开源模型在推动智能体工作流程方面表现欠佳: 虽然对于小型的 Zephyr-7b 而言这是预期之中的,但令人惊讶的是 Llama2-70b 的表现相当差。
👉 然而,Mixtral-8x7B 的表现非常出色: 它甚至超越了 GPT-3.5!🏆
这是即开即用的性能: 与 GPT-3.5 不同的是,据我们所知,Mixtral 没有针对智能体工作流程进行过微调 ,这在一定程度上影响了其性能。例如,在 GAIA 上,因为 Mixtral 尝试使用格式不正确的参数调用工具,导致 10%的问题失败。 如果对功能调用和任务规划技能进行适当的微调,Mixtral 的得分可能会更高。
➡️ 我们强烈建议开源开发者开始针对智能体对 Mixtral 进行微调,以超越下一个挑战者: GPT-4!🚀
结语:
- 虽然 GAIA 基准测试仅在一小部分问题和少数工具上进行了尝试,但它似乎是智能体工作流程整体模型性能的一个非常强大的指标,因为它通常涉及多个推理步骤和严格的逻辑。
- 智能体工作流程使 LLMs 能够提升性能: 例如,在 GSM8K 上,GPT-4 的技术报告 显示,使用 5 次 CoT 提示的情况下得分为 92%: 通过提供一个计算器,我们能够在零次提示的情况下达到 95%。对于 Mixtral-8x7B,LLM 排行榜 报告了使用 5 次提示的情况下为 57.6%,而我们在零次提示的情况下达到了 73%。 (记住,我们仅测试了 GSM8K 的 20 个问题)
赞赏英文原文: https://hf.co/blog/open-source-llms-as-agents
作者: Aymeric Roucher, Joffrey THOMAS, Andrew Reed
译者: Evinci
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...