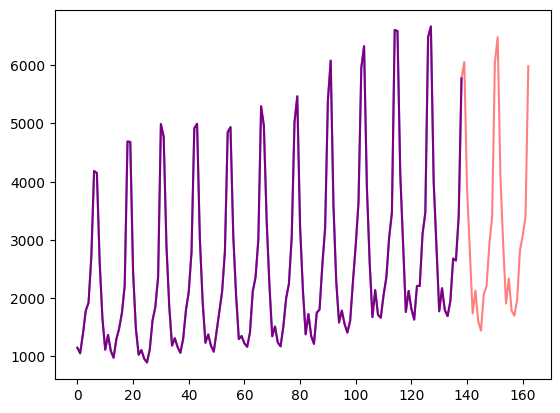
使用 🤗 Transformers 进行概率时间序列预测介绍 时间序列预测是一个重要的科学和商业问题,因此最近通过使用基于深度学习 而不是经典方法的模型也涌现出诸多创新。ARIMA 等经典方法与新颖的深度学习方法之间的一个重要区别如下。 概率预测 通常,经...AI 技术文章# Transformers3年前04400
在 Transformers 中使用对比搜索生成可媲美人类水平的文本 🤗1. 引言 自然语言生成 (即文本生成) 是自然语言处理 (NLP) 的核心任务之一。本文将介绍神经网络文本生成领域当前最先进的解码方法 对比搜索 (Contrastive Search)。提出该方法...AI 技术文章# Transformers3年前04100
在 Transformers 中使用对比搜索生成可媲美人类水平的文本🤗1. 引言 自然语言生成 (即文本生成) 是自然语言处理 (NLP) 的核心任务之一。本文将介绍神经网络文本生成领域当前最先进的解码方法 对比搜索 (Contrastive Search)。提出该方法...AI 技术文章# Transformers3年前04090
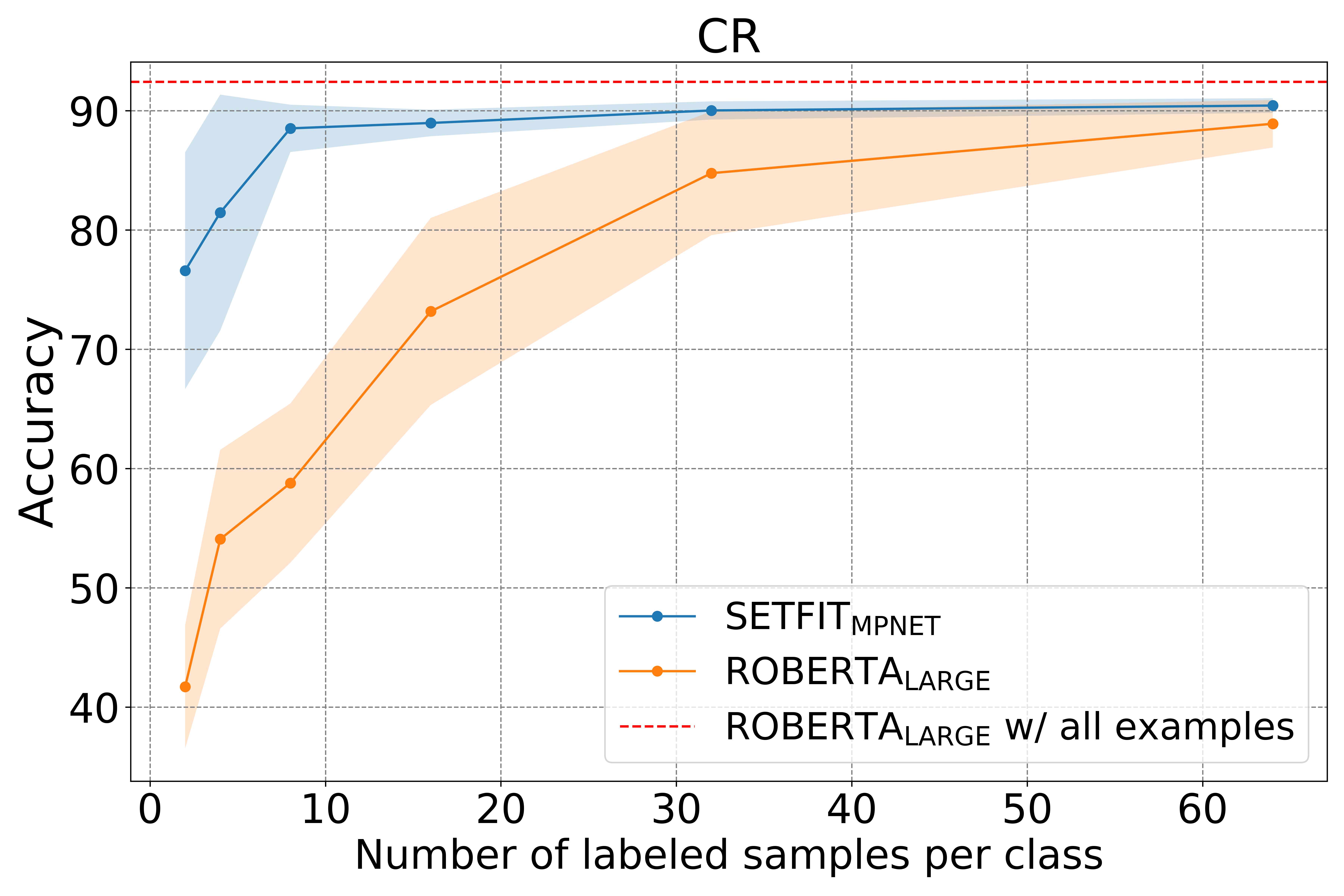
SetFit: 高效的无提示少样本学习与标准微调相比,SetFit 能更高效地利用训练样本,同时对噪声也更健壮。 如何处理少标签或无标签的训练数据是每个数据科学家的梦魇 😱。最近几年来,基于预训练语言模型的少样本 (few-shot) 学...AI 技术文章# Prompts# Transformers3年前04320
使用 Megatron-LM 训练语言模型在 PyTorch 中训练大语言模型不仅仅是写一个训练循环这么简单。我们通常需要将模型分布在多个设备上,并使用许多优化技术以实现稳定高效的训练。Hugging Face 🤗 Accelerate 的创...AI 技术文章# LLM# PyTorch# Transformers2年前04790
大规模 Transformer 模型 8 比特矩阵乘简介 – 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes引言 语言模型一直在变大。截至撰写本文时,PaLM 有 5400 亿参数,OPT、GPT-3 和 BLOOM 有大约 1760 亿参数,而且我们仍在继续朝着更大的模型发展。下图总结了最近的一些语言模型...AI 技术文章# Accelerate# bitsandbytes# Transformers3年前04240
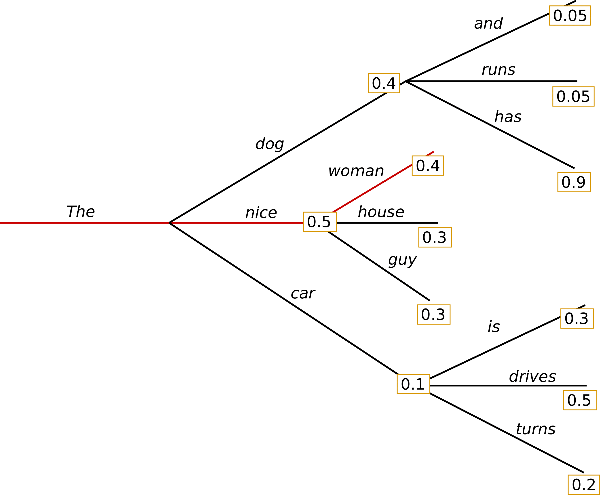
如何生成文本: 通过 Transformers 用不同的解码方法生成文本简介 近年来,随着以 OpenAI GPT2 模型 为代表的基于数百万网页数据训练的大型 Transformer 语言模型的兴起,开放域语言生成领域吸引了越来越多的关注。开放域中的条件语言生成效果令人...AI 技术文章# Transformers3年前04480