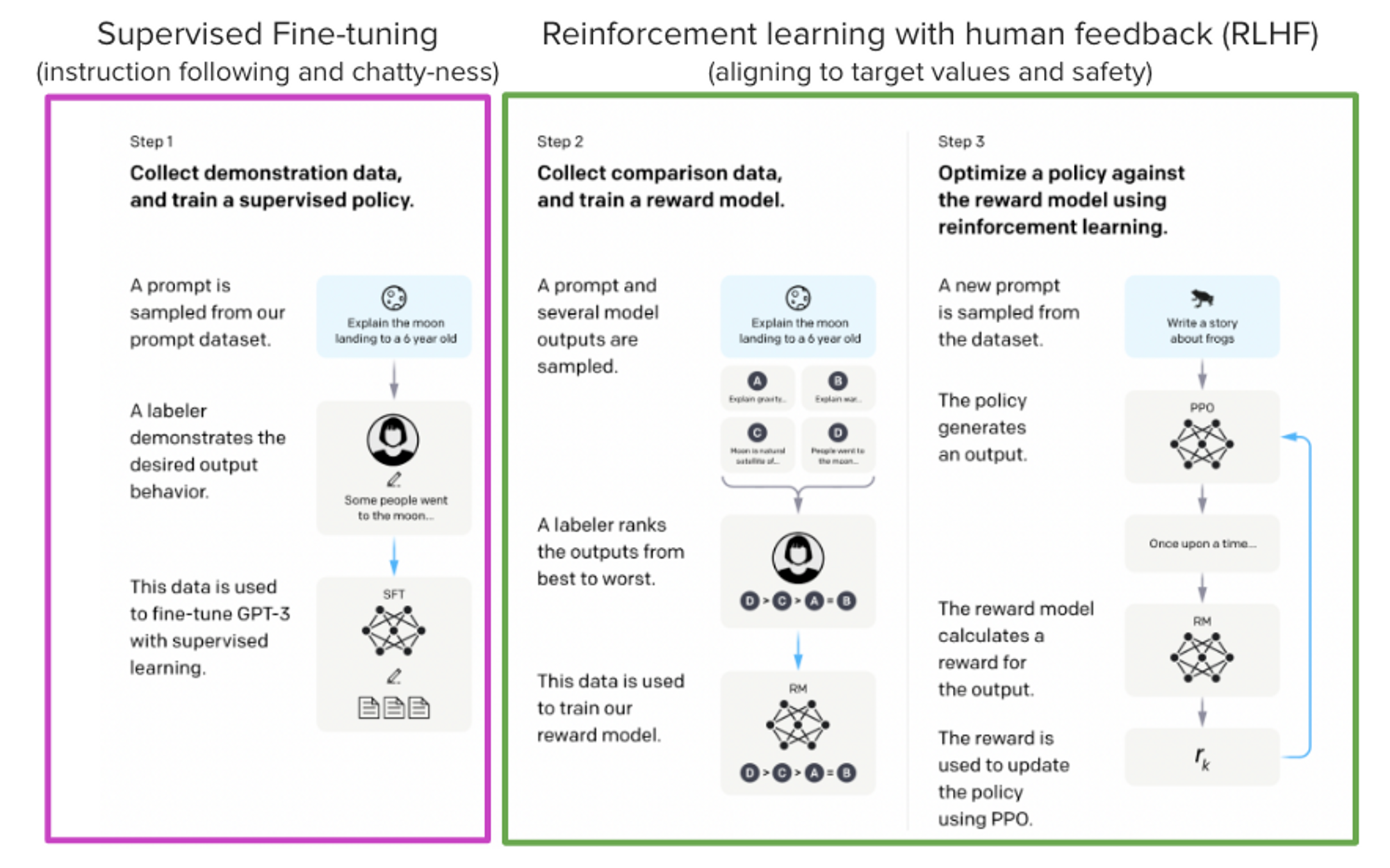
“StackLLaMA”: 用 RLHF 训练 LLaMA 的手把手教程如 ChatGPT,GPT-4,Claude语言模型 之强大,因为它们采用了 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF...AI 技术文章# LLaMA# RLHF# StackLLaMA2年前03930