将强化学习重新引入 RLHF我们很高兴在 TRL 中介绍 RLOO (REINFORCE Leave One-Out) 训练器。作为一种替代 PPO 的方法,RLOO 是一种新的在线 RLHF 训练算法,旨在使其更易于访问和实施...AI 技术文章# RLHF# 强化学习2年前02480
使用 PPO 算法进行 RLHF 的 N 步实现细节当下,RLHF/ChatGPT 已经变成了一个非常流行的话题。我们正在致力于更多有关 RLHF 的研究,这篇博客尝试复现 OpenAI 在 2019 年开源的原始 RLHF 代码库,其仓库位置位于 o...AI 技术文章# PPO# PPO算法# RLHF2年前03690
“StackLLaMA”: 用 RLHF 训练 LLaMA 的手把手教程如 ChatGPT,GPT-4,Claude语言模型 之强大,因为它们采用了 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF...AI 技术文章# LLaMA# RLHF# StackLLaMA2年前03960
在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案。 请注意, ...AI 技术文章# LLM# RLHF3年前04420
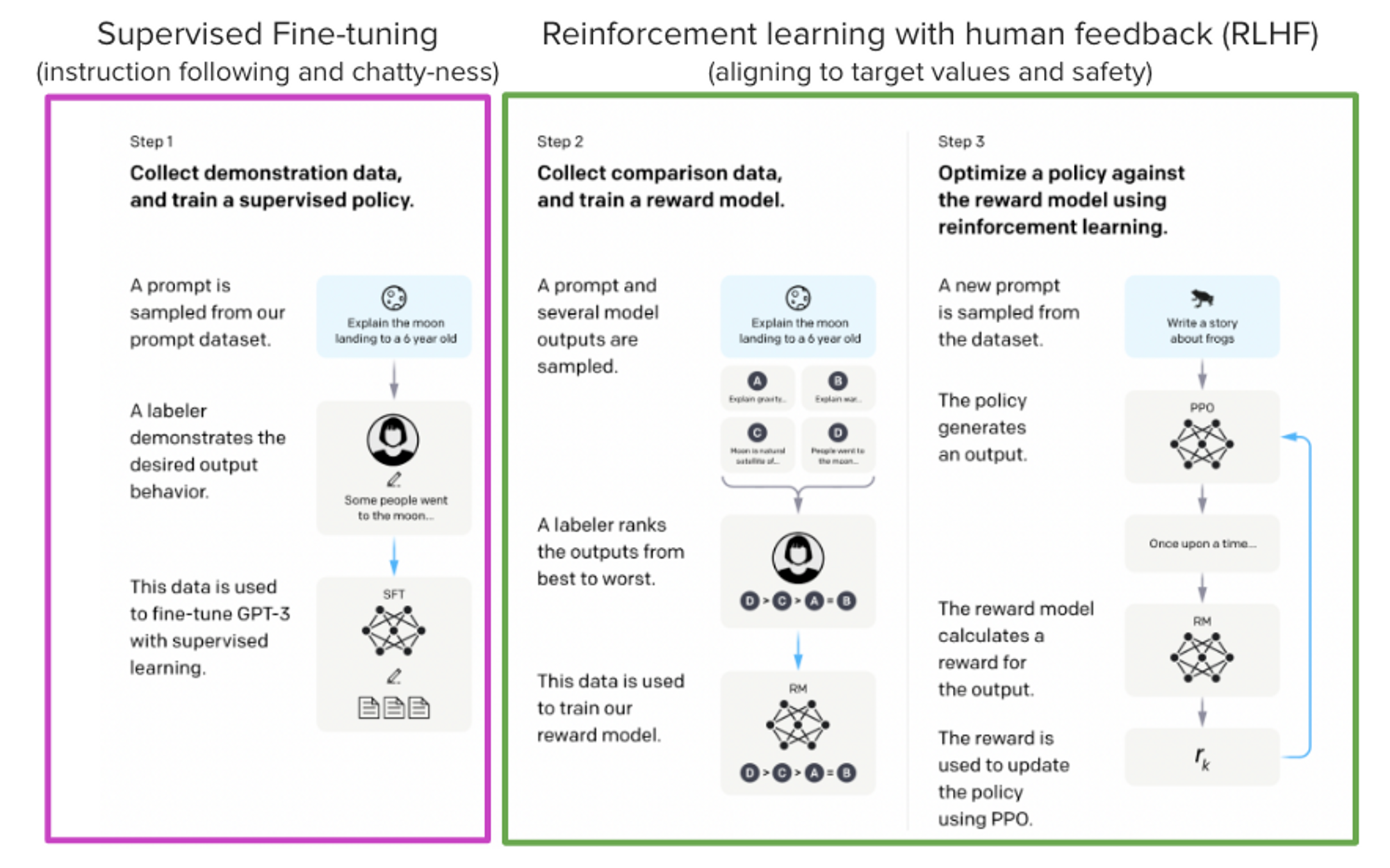
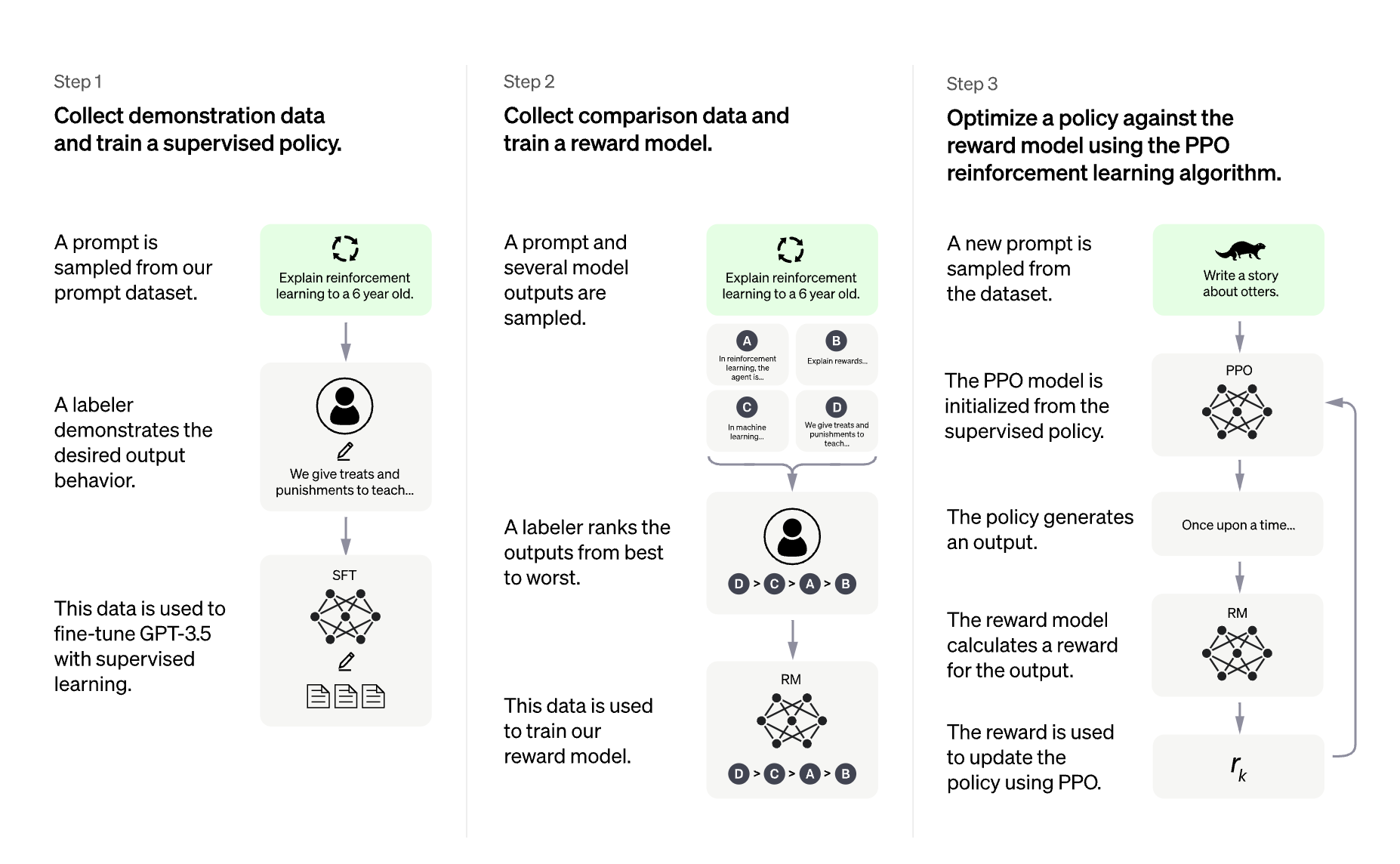
ChatGPT 背后的「功臣」——RLHF 技术详解OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界。这一工作的背后是大型语言模型 (Large Language Mode...AI 技术文章# ChatGPT# RLHF3年前04080