Accelerate 1.0.0Accelerate 发展概况 在三年半以前、项目发起之初时,Accelerate 的目标还只是制作一个简单框架,通过一个低层的抽象来简化多 GPU 或 TPU 训练,以此替代原生的 PyTorch ...AI 技术文章# Accelerate1年前02300
使用 PyTorch FSDP 微调 Llama 2 70B引言 通过本文,你将了解如何使用 PyTorch FSDP 及相关最佳实践微调 Llama 2 70B。在此过程中,我们主要会用到 Hugging Face Transformers、Accelera...AI 技术文章# Accelerate# FSDP# Llama 2 70B2年前03570
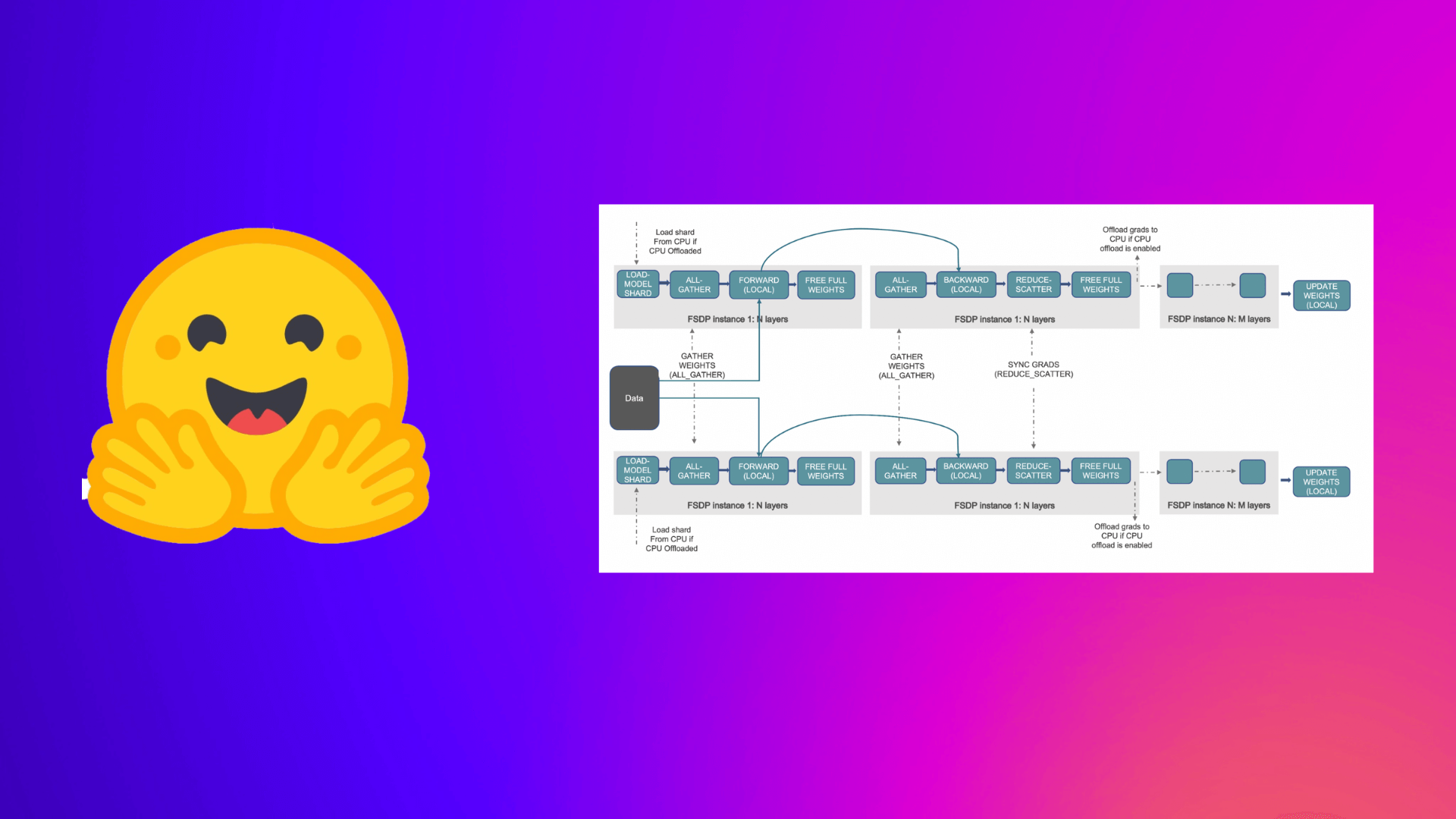
使用 PyTorch 完全分片数据并行技术加速大模型训练本文,我们将了解如何基于 PyTorch 最新的 完全分片数据并行 (Fully Sharded Data Parallel,FSDP) 功能用 Accelerate 库来训练大模型。 动机 🤗 随着...AI 技术文章# Accelerate# Accelerate 库# FSDP2年前03730
从 PyTorch DDP 到 Accelerate 到 Trainer,轻松掌握分布式训练概述 本教程假定你已经对于 PyToch 训练一个简单模型有一定的基础理解。本教程将展示使用 3 种封装层级不同的方法调用 DDP (DistributedDataParallel) 进程,在多个 G...AI 技术文章# Accelerate# PyTorch# Trainer3年前04060
使用 DeepSpeed 和 Accelerate 进行超快 BLOOM 模型推理本文展示了如何使用 1760 亿 (176B) 参数的 BLOOM 模型 生成文本时如何获得超快的词吞吐 (per token throughput)。 因为在使用 bf16 (bfloat16) 权...AI 技术文章# Accelerate# BLOOM# DeepSpeed2年前04270
大规模 Transformer 模型 8 比特矩阵乘简介 – 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes引言 语言模型一直在变大。截至撰写本文时,PaLM 有 5400 亿参数,OPT、GPT-3 和 BLOOM 有大约 1760 亿参数,而且我们仍在继续朝着更大的模型发展。下图总结了最近的一些语言模型...AI 技术文章# Accelerate# bitsandbytes# Transformers3年前04240