SetFitABSA: 基于 SetFit 的少样本、方面级情感分析SetFitABSA 是一种可以有效从文本中检测方面级情感的技术。 方面级情感分析 (Aspect-Based Sentiment Analysis,ABSA) 是一种检测文本中特定方面的情感的任务...AI 技术文章# SetFit# SetFitABSA2年前03650
给科研人的 ML 开源发布工具包什么是开源发布工具包? 恭喜你的论文成功发表,这是一个巨大的成就!你的研究成果将为学界做出贡献。 其实除了发表论文之外,你还可以通过发布研究的其他部分,如代码、数据集、模型等,来增加研究的可见度和采用...AI 技术文章# ML# 工具包2年前03810
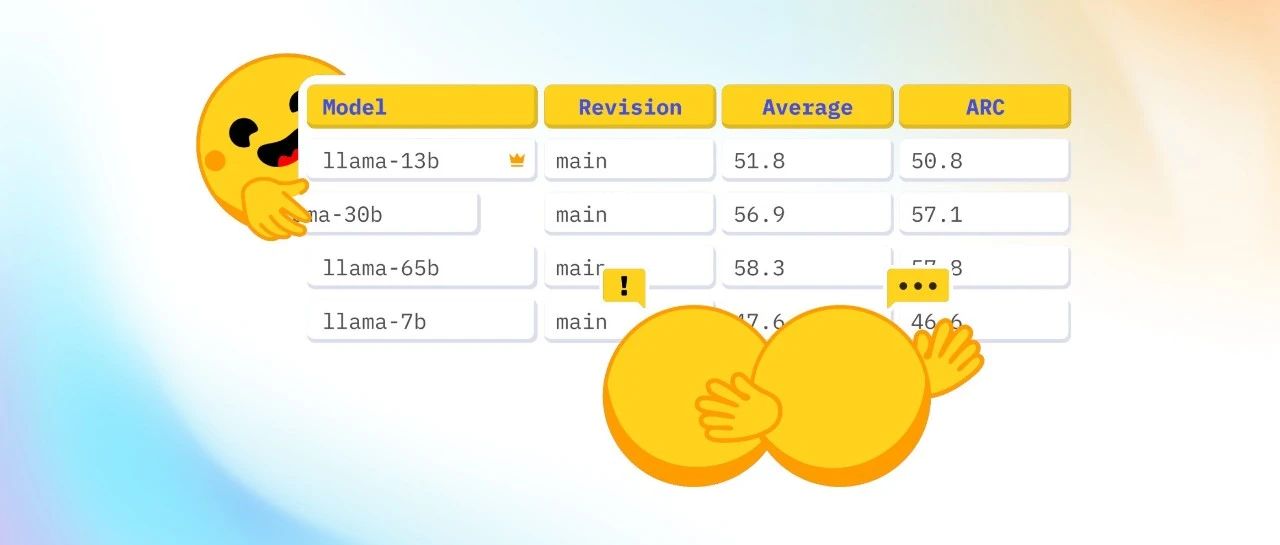
开放 LLM 排行榜: 深入研究 DROP最近,开放 LLM 排行榜 迎来了 3 个新成员: Winogrande、GSM8k 以及 DROP,它们都使用了 EleutherAI Harness 的原始实现。一眼望去,我们就会发现 DROP ...AI 技术文章# DROP# LLM2年前14100
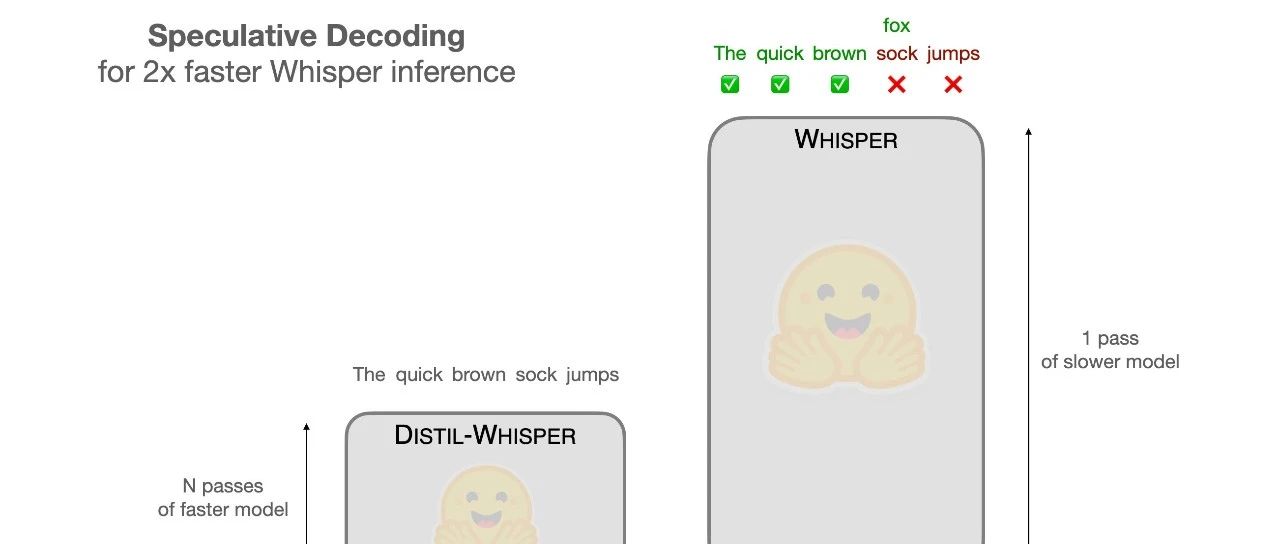
使用推测解码 (Speculative Decoding) 使 Whisper 实现 2 倍的推理加速Open AI 推出的 Whisper 是一个通用语音转录模型,在各种基准和音频条件下都取得了非常棒的结果。最新的 large-v3 模型登顶了 OpenASR 排行榜,被评为最佳的开源英语语音转录模...AI 技术文章# Whisper# 推理加速2年前03410
非工程师指南: 训练 LLaMA 2 聊天机器人引言 本教程将向你展示在不编写一行代码的情况下,如何构建自己的开源 ChatGPT,这样人人都能构建自己的聊天模型。我们将以 LLaMA 2 基础模型为例,在开源指令数据集上针对聊天场景对其进行微调...AI 技术文章# Llama 2# 聊天机器人2年前03750
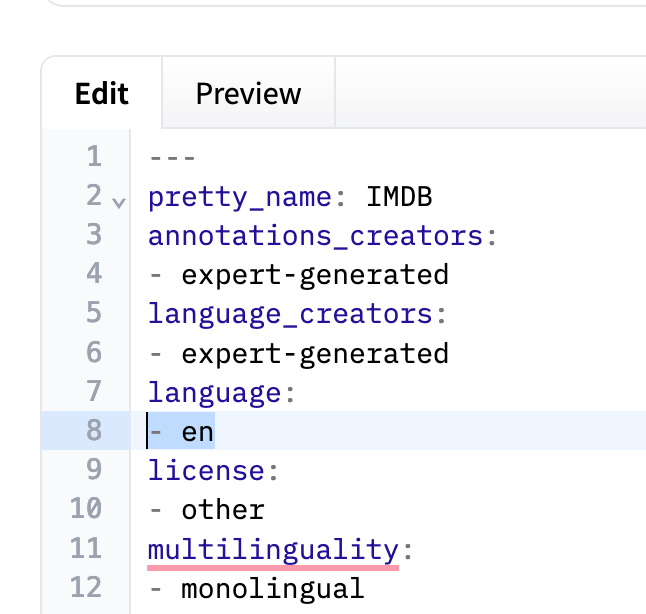
Huggy Lingo: 利用机器学习改进 Hugging Face Hub 上的语言元数据太长不看版: Hub 上有不少数据集没有语言元数据,我们用机器学习来检测其语言,并使用 librarian-bots 自动向这些数据集提 PR 以添加其语言元数据。 Hugging Face Hub ...AI 技术文章# Hugging Face Hub# Huggy Lingo# 语言元数据2年前03590
欢迎 Mixtral – 当前 Hugging Face 上最先进的 MoE 模型最近,Mistral 发布了一个激动人心的大语言模型: Mixtral 8x7b,该模型把开放模型的性能带到了一个新高度,并在许多基准测试上表现优于 GPT-3.5。我们很高兴能够在 Hugging ...AI 技术文章# GPTQ# Mixtral# MoE 模型2年前03680
Hugging Face 年度回顾:2023,开源大模型之年在 2023 年,大型语言模型(Large Language Models,简称 LLMs)受到了公众的广泛关注,许多人对这些模型的本质及其功能有了基本的了解。是否开源的议题同样引起了广泛的讨论。在 ...AI 技术文章# Hugging Face# LLM2年前03720
Reformer 模型 – 突破语言建模的极限Reformer 如何在不到 8GB 的内存上训练 50 万个词元 Kitaev、Kaiser 等人于 20202 年引入的 Reformer 模型 是迄今为止长序列建模领域内存效率最高的 trans...AI 技术文章# LSH# Reformer# Reformer 模型2年前03510
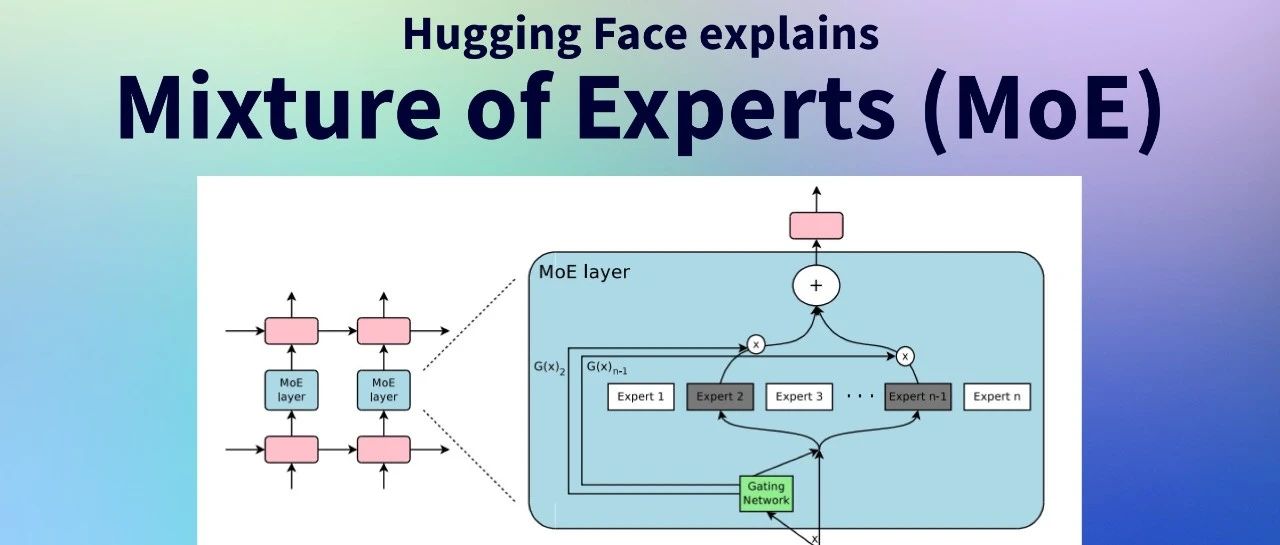
混合专家模型 (MoE) 详解随着 Mixtral 8x7B (announcement, model card) 的推出,一种称为混合专家模型 (Mixed Expert Models,简称 MoEs) 的 Transforme...AI 技术文章# MoE# 混合专家模型2年前03840