
内容目录
自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制。该方法出自论文 LayerSkip: Enabling Early-Exit Inference and Self-Speculative Decoding。它通过使用 同一个模型 的早期层来生成候选词元 (token),并使用后期层进行验证,从而实现高效生成。
这项技术不仅加快了文本生成速度,还显著节省了内存并降低了计算延迟。为了实现端到端的加速,早期层的输出需要与最终层的输出足够接近。正如论文中所述,这可以通过一种训练方法来实现,该方法可以在预训练期间应用,也可以在特定领域进行微调时应用。自推测解码对于实际应用特别高效,它可以在较小的 GPU 上部署,并降低 大规模推理 所需的整体硬件资源。
在本博客中,我们将探讨自推测解码的概念、其实现方式以及在 🤗 transformers 库中的实际应用。您将了解到其技术原理,包括 提前退出层 (Early-Exit Layers) 、 反嵌入 (Unembedding) 和 训练修改 (Training Modifications)。为了将这些概念付诸实践,我们提供了代码示例、与传统推测解码的基准比较,以及对性能权衡的见解。
您还可以直接查看以下 Hugging Face 资源,了解更多关于该方法的信息并亲自尝试:
推测解码与自推测解码

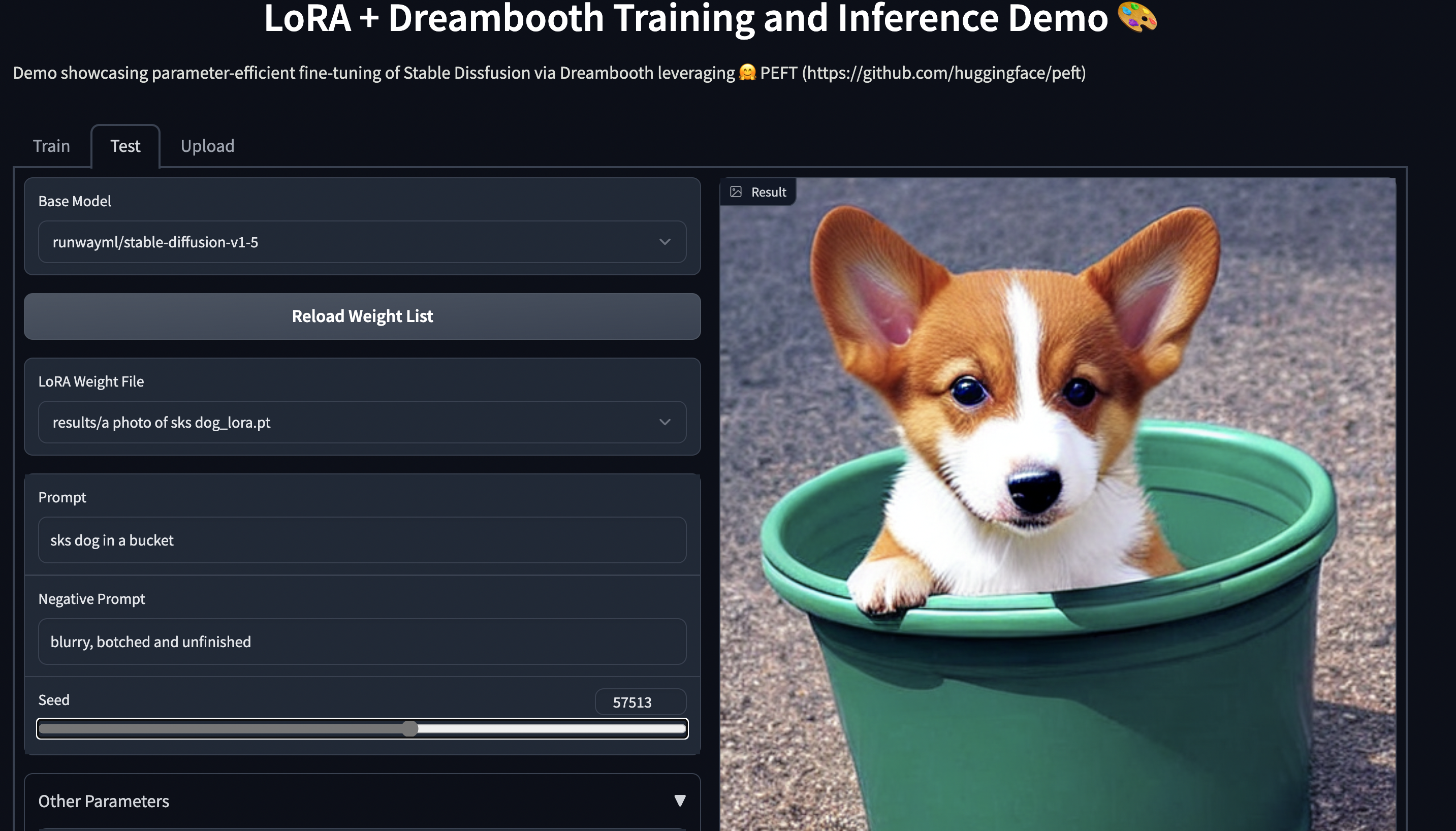
_在 facebook/layerskip-llama2-7B 上的 LayerSkip 推理演示 (使用 LayerSkip 方法持续预训练的 Llama2 7B)。_
传统的推测解码 使用 两个 模型: 一个较小的模型 (草稿模型) 用于生成一系列候选词元,一个较大的模型 (验证模型) 用于验证草稿的准确性。较小的模型执行大部分生成工作,而较大的模型则负责改进结果。这提高了文本生成速度,因为较大的模型一次性验证完整序列,而不是逐个生成词元。
在自推测解码中,作者在此概念的基础上,使用大模型的早期层来生成草稿词元,然后由模型的更深层进行验证。这种推测解码的“自洽”特性需要特定的训练,使模型能够同时执行草稿生成和验证。这反过来又比传统的推测解码提高了速度并降低了计算成本。
在 transformers 中的使用
为了在 🤗 transformers 库中启用提前退出自推测解码,我们只需在 generate() 函数中添加 assistant_early_exit 参数。
以下是一个简单的代码片段,展示了该功能:
pip install transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
early_exit_layer = 4
prompt = "Alice and Bob"
checkpoint = "facebook/layerskip-llama2-7B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
model = AutoModelForCausalLM.from_pretrained(checkpoint).to("cuda")
outputs = model.generate(**inputs, assistant_early_exit=early_exit_layer)注意: 虽然 assistant_early_exit 参数可以为任何仅解码器的 transformer 启用提前退出自推测解码,但除非模型经过专门训练,否则无法反嵌入 (通过 LM 头进行解码的过程,在博客文章后面有描述) 中间层的 logits。只有对检查点进行这样的训练,以提高早期层的准确性,您才能获得加速。LayerSkip 论文提出了一种训练方法来实现这一点 (即应用提前退出损失,并逐步增加层丢弃率)。这里 提供了使用 LayerSkip 训练方法持续预训练的 Llama2、Llama3 和 Code Llama 检查点的集合。
基准测试
我们进行了一系列广泛的基准测试,以衡量 LayerSkip 的自推测解码相对于自回归解码在各种模型上的加速情况。我们还将自推测解码 (基于提前退出) 与标准推测解码技术进行了比较。要复现这些结果,您可以在 这里 找到代码,并在 此电子表格 中找到运行每个实验的命令。所有实验均在单个 80GB A100 GPU 上运行,除了 Llama2 70B 实验在 8 个 A100 GPU 的节点上运行。
Llama3.2 1B
| Model Variant (模型变体) | Layers (层数) | Assistant Model (辅助模型) | Assistant Layers (辅助层数) | Task (任务) | Total Layers (总层数) | FLOPs/Input (G) (输入 FLOPs) | Time/Input (s) (输入时间) | FLOPs/Output (G) (输出 FLOPs) | Time/Output (s) (输出时间) | Efficiency (效率) |
|---|---|---|---|---|---|---|---|---|---|---|
| facebook/layerskip-llama3.2-1B | 1 | Early Exit @ Layer 4 | summarization | 1 | 1195.28 | 9.96 | 2147.7 | 17.9 | 1.80 |
Llama3 8B
| Model Variant (模型变体) | Layers (层数) | Assistant Model (辅助模型) | Assistant Layers (辅助层数) | Task (任务) | Total Layers (总层数) | FLOPs/Input (G) (输入 FLOPs) | Time/Input (s) (输入时间) | FLOPs/Output (G) (输出 FLOPs) | Time/Output (s) (输出时间) | Efficiency (效率) |
|---|---|---|---|---|---|---|---|---|---|---|
| meta-llama/Meta-Llama-3-8B | 8 | meta-llama/Llama-3.2-1B | 1 | summarization | 9 | 1872.46 | 19.04 | 2859.35 | 29.08 | 1.53 |
| meta-llama/Meta-Llama-3-8B | 8 | meta-llama/Llama-3.2-3B | 3 | summarization | 11 | 2814.82 | 28.63 | 2825.36 | 28.73 | 1.00 |
| facebook/layerskip-llama3-8B | 8 | Early Exit @ Layer 4 | summarization | 8 | 1949.02 | 15.75 | 3571.81 | 28.87 | 1.83 |
Llama2 70B
| Model Variant (模型变体) | Layers (层数) | Assistant Model (辅助模型) | Assistant Layers (辅助层数) | Task (任务) | Total Layers (总层数) | FLOPs/Input (G) (输入 FLOPs) | Time/Input (s) (输入时间) | FLOPs/Output (G) (输出 FLOPs) | Time/Output (s) (输出时间) | Efficiency (效率) |
|---|---|---|---|---|---|---|---|---|---|---|
| meta-llama/Llama-2-70b-hf | 70 | meta-llama/Llama-2-13b-hf | 13 | summarization | 83 | 5036.54 | 46.3 | 12289.01 | 112.97 | 2.44 |
| meta-llama/Llama-2-70b-hf | 70 | meta-llama/Llama-2-7b-hf | 7 | summarization | 77 | 4357.55 | 40.06 | 12324.19 | 113.3 | 2.83 |
| meta-llama/Llama-2-70b-hf | 70 | TinyLlama/TinyLlama_v1.1 | 1 | summarization | 71 | 4356.21 | 40.05 | 12363.22 | 113.66 | 2.84 |
| facebook/layerskip-llama2-70B | 70 | Early Exit @ Layer 10 | summarization | 70 | 6012.04 | 54.96 | 1283.34 | 113.2 | 2.06 |
Llama2 13B
| Model Variant (模型变体) | Layers (层数) | Assistant Model (辅助模型) | Assistant Layers (辅助层数) | Task (任务) | Total Layers (总层数) | FLOPs/Input (G) (输入 FLOPs) | Time/Input (s) (输入时间) | FLOPs/Output (G) (输出 FLOPs) | Time/Output (s) (输出时间) | Efficiency (效率) |
|---|---|---|---|---|---|---|---|---|---|---|
| meta-llama/Llama-2-13b-hf | 13 | meta-llama/Llama-2-7b-hf | 7 | summarization | 20 | 3557.07 | 27.79 | 4088.48 | 31.94 | 1.15 |
| meta-llama/Llama-2-13b-hf | 13 | TinyLlama/TinyLlama_v1.1 | 1 | summarization | 14 | 2901.92 | 22.67 | 4190.42 | 32.74 | 1.44 |
| meta-llama/Llama-2-13b-hf | 13 | apple/OpenELM-270M | 0.27 | summarization | 13.27 | 2883.33 | 22.53 | 4521.12 | 35.32 | 1.57 |
| meta-llama/Llama-2-13b-hf | 13 | apple/OpenELM-450M | 0.45 | summarization | 13.45 | 3267.69 | 25.53 | 4321.75 | 33.76 | 1.32 |
| facebook/layerskip-llama2-13B | 13 | Early Exit @ Layer 4 | summarization | 13 | 4238.45 | 33.11 | 4217.78 | 32.95 | 0.995 | |
| facebook/layerskip-llama2-13B | 13 | Early Exit @ Layer 8 | summarization | 13 | 2459.61 | 19.22 | 4294.98 | 33.55 | 1.746 |
Llama2 7B
| Model Variant (模型变体) | Layers (层数) | Assistant Model (辅助模型) | Assistant Layers (辅助层数) | Task (任务) | Total Layers (总层数) | FLOPs/Input (G) (输入 FLOPs) | Time/Input (s) (输入时间) | FLOPs/Output (G) (输出 FLOPs) | Time/Output (s) (输出时间) | Efficiency (效率) |
|---|---|---|---|---|---|---|---|---|---|---|
| meta-llama/Llama-2-7b-hf | 7 | TinyLlama/TinyLlama_v1.1 | 1 | summarization | 8 | 2771.54 | 21.65 | 3368.48 | 26.32 | 1.22 |
| meta-llama/Llama-2-7b-hf | 7 | apple/OpenELM-270M | 0.27 | summarization | 7.27 | 2607.82 | 20.37 | 4221.14 | 32.98 | 1.62 |
| meta-llama/Llama-2-7b-hf | 7 | apple/OpenELM-450M | 0.45 | summarization | 7.45 | 3324.68 | 25.97 | 4178.66 | 32.65 | 1.26 |
| facebook/layerskip-llama2-7B | 7 | Early Exit @ Layer 4 | summarization | 7 | 2548.4 | 19.91 | 3306.73 | 25.83 | 1.297 |
我们可以观察到以下几点:
- 从“ 总参数数量”列可以看出,自推测解码消耗的内存更少,因为它不需要单独的草稿模型,并且草稿阶段层的权重被重用。
- 对于除 Llama2 70B 之外的所有模型大小和生成,提前退出自推测解码比常规的两模型推测解码更快。
- 与其它模型相比,Llama2 70B 的自推测解码速度提升相对有限,可能有不同的原因,例如,Llama2 70B 的 LayerSkip 检查点持续预训练的 token 较少 (Llama2 70B 为 328M token,而 Llama2 7B 为 52B token)。但这是未来研究需要改进的一个方面。尽管如此,70B 的自推测解码明显快于自回归解码。
自生成和自验证
自推测解码过程从自生成开始,其中词元是通过从某个中间层提前退出来生成的。推测词元的数量定义了在此阶段生成多少草稿词元,而我们退出的层定义了草稿阶段的规模和准确性。这两个参数都可以在推理时根据草稿阶段的速度和准确性之间的权衡来指定。
下一步是自验证,其中使用完整模型来验证草稿词元。验证模型重用草稿模型中的缓存部分。如果草稿词元与验证的词元一致,则将它们添加到最终输出中,从而更好地利用我们系统中的内存带宽,因为使用完整模型生成一系列词元比验证草稿要昂贵得多,只要有几个词元匹配即可。
在自验证阶段,只有剩余的层才会被计算以进行验证,因为早期层的结果在草稿阶段已被缓存。
提前退出和反嵌入
自推测解码中的一项关键技术是提前退出,即生成过程可以在预先指定的层停止。为了实现这一点,我们通过将这些层的 logits 投影到语言模型 (LM) 头上来反嵌入它们,以预测下一个词元。这允许模型跳过后续层并提高推理时间。
可以在任何 transformer 层执行反嵌入,将提前退出转变为一种高效的词元预测机制。一个自然而然的问题出现了: 当 LM 头最初被训练为仅与最终层一起工作时,如何使其适应反嵌入较早层的 logits?这就是训练修改发挥作用的地方。
训练修改
在训练阶段,我们引入了层丢弃,它允许模型在训练期间跳过某些层。丢弃率在较深的层中逐渐增加,使模型不太依赖其后面的层,并增强模型的泛化能力并加快训练速度。
除了层丢弃之外,还应用了提前退出损失,以确保 LM 头学习反嵌入不同的层。使用每个出口 (中间层) 的归一化损失的总和来给出使用提前出口训练模型的总损失函数。这种技术通过在所有层之间分配学习任务来实现高效训练。
优化: 共享权重、共享 KV 缓存和共享计算
自推测解码显著受益于缓存重用,特别是 KV 缓存,它存储在草稿阶段计算的键值对。此缓存允许模型跳过冗余计算,因为草稿和验证阶段都使用相同的早期层。此外,退出查询缓存存储来自退出层的查询向量,允许验证从草稿阶段无缝继续。
与传统的双模型推测解码相比,提前退出自推测解码可以从以下节省中受益:
- 共享权重: 为草稿和验证重用前 E 层 的权重。
- 共享 KV 缓存: 为草稿和验证重用前 E 层的键值对
- 共享计算: 通过使用仅保存退出层 E-1 的查询向量的退出查询缓存来重用前 E 层的计算,以便验证过程无需计算层 0 到 E-1。
KV 和退出查询缓存的组合称为 KVQ 缓存,可减少内存开销并提高推理延迟。
到目前为止,🤗 transformers 库已在此 pull request 中实现了第一个优化 (共享权重)。随着使用此方法的模型数量增加,我们将考虑其他优化。如果您有兴趣,请随时提出 PR!
提前退出层的选择策略
草稿阶段的提前退出层是一个超参数,我们可以在推理期间调整或修改:
- 我们越早退出,生成草稿词元的速度就越快,但它们的准确性就越低。
- 我们越晚退出,生成的草稿词元就越准确,但它们的速度就越慢。
我们编写了一个脚本来遍历不同的提前退出层并测量 A100 GPU 上的每秒词元数。在下面的表格中,我们绘制了针对不同 Llama 模型的 LayerSkip 和基线检查点的每秒词元数与提前退出层的关系图 (您可以在 此处 查看完整日志)。
Llama3.2 1B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
Llama3 8B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
Code Llama3 34B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
Code Llama3 7B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
Llama2 70B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
Llama2 13B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
Llama2 7B
| Normal (常规模型) | LayerSkip (LayerSkip 模型) |
|---|---|
 |  |
我们可以观察到以下几点:
- 对于没有使用 LayerSkip 训练方法进行预训练或持续预训练的基线检查点,提前退出自推测解码比自回归解码更慢。这是因为在大多数 LLM 的训练过程中,早期层并没有被激励去学习预测输出,因此使用早期层生成词元的接受率会非常低。
- 另一方面,对于使用 LayerSkip 训练方法持续预训练的 Llama 检查点,提前退出自推测解码在至少一部分层中比自回归解码具有更高的加速比。
- 对于大多数模型 (除了 Llama3.2 1B),当我们遍历各层时,我们注意到一个规律模式: 加速比在前几层较低,逐渐增加到一个最佳点,然后再次下降。
- 提前退出层的最佳点是在预测的高准确性和生成词元的低开销之间达到最佳权衡时。这个最佳点取决于每个模型,也可能取决于提示或提示的领域。
这些观察为进一步的实验和探索提供了有趣的机会。我们鼓励读者在这些想法的基础上进行构建,测试变体,并进行自己的研究。这些努力可以带来有价值的见解,并为该领域做出有意义的贡献。
结论
LayerSkip 利用提前退出、层丢弃和缓存重用之间的协同作用,创建了一个快速高效的文本生成流程。通过训练模型从不同层反嵌入输出,并使用缓存优化验证过程,这种方法在速度和准确性之间取得了平衡。因此,它显著改善了大语言模型的推理时间,同时保持了高质量的输出。由于使用单个模型作为草稿和验证模型,它还比传统的推测解码技术减少了内存使用。
自推测是一个令人兴奋的领域,同一个 LLM 可以创建草稿词元并自我修正。其他自推测方法包括:
- Draft & Verify: 其中草稿阶段涉及跳过预定的注意力和前馈层。
- MagicDec: 其中草稿阶段使用 KV 缓存的子集,这对长上下文输入很有用。
- Jacobi Decoding 和 Lookahead Decoding: 其中草稿阶段是一系列“猜测词元”,可以是随机的或从 n-gram 查找表中获得的。
赞赏英文原文: https://huggingface.co/blog/layerskip
原文作者: Aritra Roy Gosthipaty, Mostafa Elhoushi, Pedro Cuenca, Vaibhav Srivastav
译者: smartisan
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...